 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian nonparametric estimation of coverage probabilities and distinct counts from sketched data
Paper and Code
Sep 05, 2022


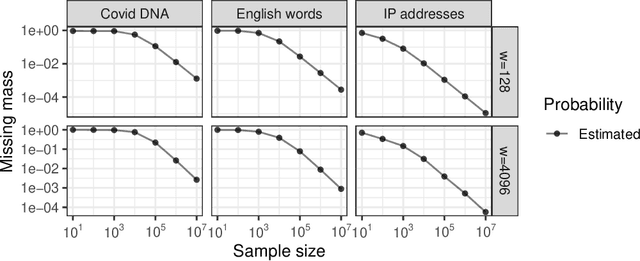
The estimation of coverage probabilities, and in particular of the missing mass, is a classical statistical problem with applications in numerous scientific fields. In this paper, we study this problem in relation to randomized data compression, or sketching. This is a novel but practically relevant perspective, and it refers to situations in which coverage probabilities must be estimated based on a compressed and imperfect summary, or sketch, of the true data, because neither the full data nor the empirical frequencies of distinct symbols can be observed directly. Our contribution is a Bayesian nonparametric methodology to estimate coverage probabilities from data sketched through random hashing, which also solves the challenging problems of recovering the numbers of distinct counts in the true data and of distinct counts with a specified empirical frequency of interest. The proposed Bayesian estimators are shown to be easily applicable to large-scale analyses in combination with a Dirichlet process prior, although they involve some open computational challenges under the more general Pitman-Yor process prior. The empirical effectiveness of our methodology is demonstrated through numerical experiments and applications to real data sets of Covid DNA sequences, classic English literature, and IP addresses.