 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Free Energy of Deep ReLU Neural Network in Overparametrized Cases
Paper and Code
Apr 20, 2023
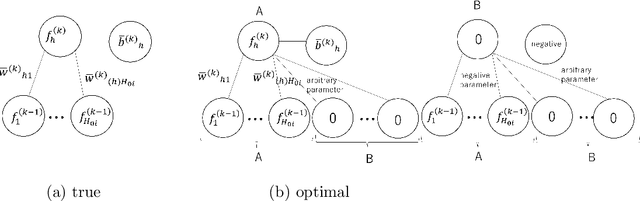
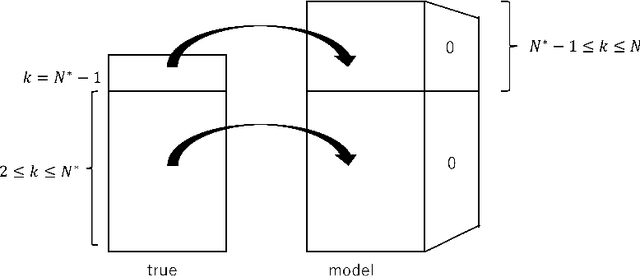
In many research fields in artificial intelligence, it has been shown that deep neural networks are useful to estimate unknown functions on high dimensional input spaces. However, their generalization performance is not yet completely clarified from the theoretical point of view because they are nonidentifiable and singular learning machines. Moreover, a ReLU function is not differentiable, to which algebraic or analytic methods in singular learning theory cannot be applied. In this paper, we study a deep ReLU neural network in overparametrized cases and prove that the Bayesian free energy, which is equal to the minus log marginal likelihoodor the Bayesian stochastic complexity, is bounded even if the number of layers are larger than necessary to estimate an unknown data-generating function. Since the Bayesian generalization error is equal to the increase of the free energy as a function of a sample size, our result also shows that the Bayesian generalization error does not increase even if a deep ReLU neural network is designed to be sufficiently large or in an opeverparametrized state.