 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian experimental design using regularized determinantal point processes
Paper and Code
Jun 10, 2019
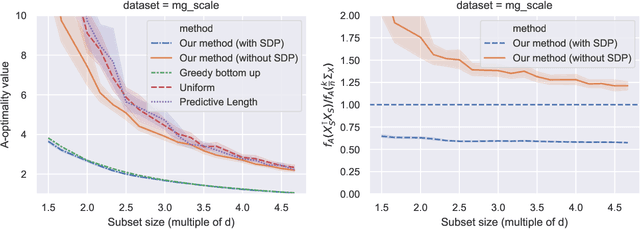
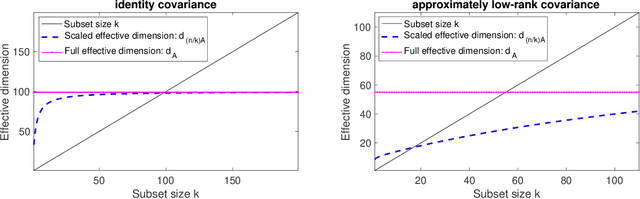

In experimental design, we are given $n$ vectors in $d$ dimensions, and our goal is to select $k\ll n$ of them to perform expensive measurements, e.g., to obtain labels/responses, for a linear regression task. Many statistical criteria have been proposed for choosing the optimal design, with popular choices including A- and D-optimality. If prior knowledge is given, typically in the form of a $d\times d$ precision matrix $\mathbf A$, then all of the criteria can be extended to incorporate that information via a Bayesian framework. In this paper, we demonstrate a new fundamental connection between Bayesian experimental design and determinantal point processes, the latter being widely used for sampling diverse subsets of data. We use this connection to develop new efficient algorithms for finding $(1+\epsilon)$-approximations of optimal designs under four optimality criteria: A, C, D and V. Our algorithms can achieve this when the desired subset size $k$ is $\Omega(\frac{d_{\mathbf A}}{\epsilon} + \frac{\log 1/\epsilon}{\epsilon^2})$, where $d_{\mathbf A}\leq d$ is the $\mathbf A$-effective dimension, which can often be much smaller than $d$. Our results offer direct improvements over a number of prior works, for both Bayesian and classical experimental design, in terms of algorithm efficiency, approximation quality, and range of applicable criteria.