 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian deep learning for mapping via auxiliary information: a new era for geostatistics?
Paper and Code
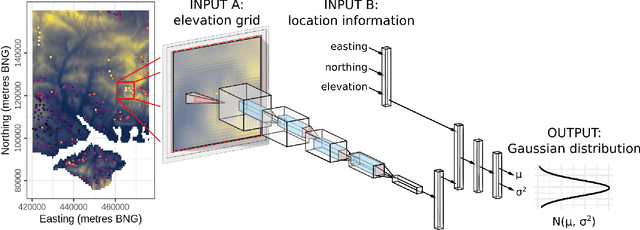
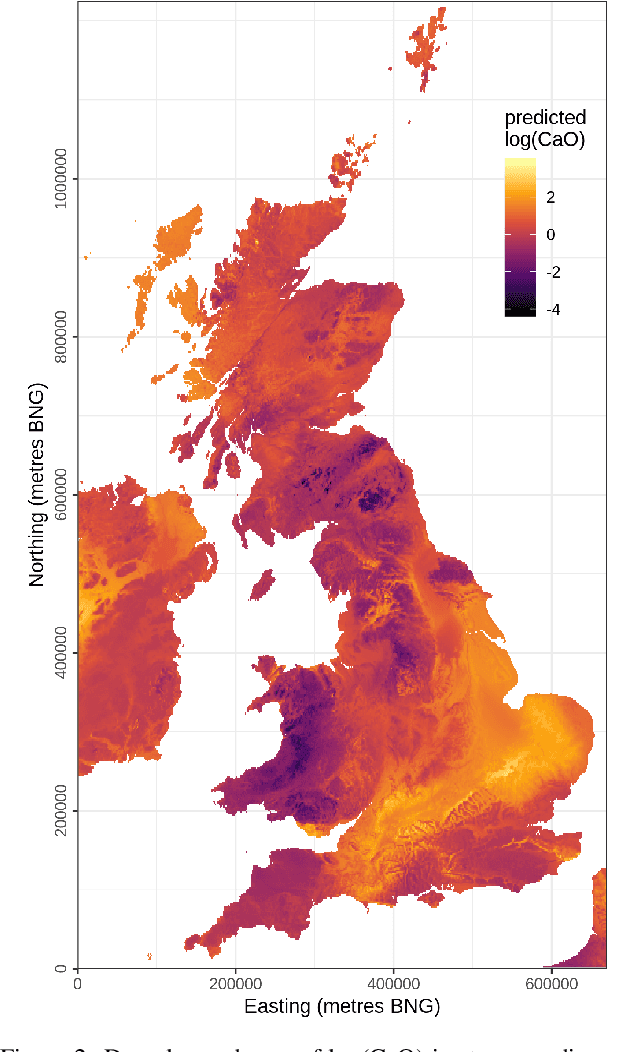
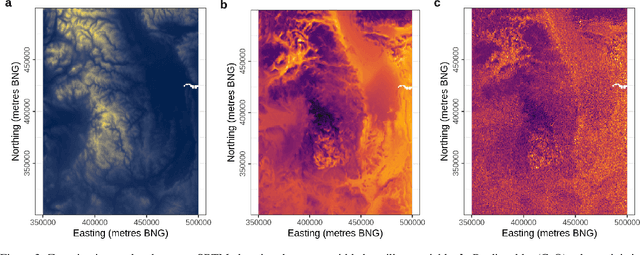
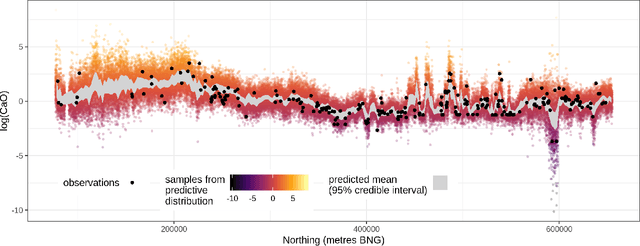
For geospatial modelling and mapping tasks, variants of kriging - the spatial interpolation technique developed by South African mining engineer Danie Krige - have long been regarded as the established geostatistical methods. However, kriging and its variants (such as regression kriging, in which auxiliary variables or derivatives of these are included as covariates) are relatively restrictive models and lack capabilities that have been afforded to us in the last decade by deep neural networks. Principal among these is feature learning - the ability to learn filters to recognise task-specific patterns in gridded data such as images. Here we demonstrate the power of feature learning in a geostatistical context, by showing how deep neural networks can automatically learn the complex relationships between point-sampled target variables and gridded auxiliary variables (such as those provided by remote sensing), and in doing so produce detailed maps of chosen target variables. At the same time, in order to cater for the needs of decision makers who require well-calibrated probabilities, we obtain uncertainty estimates via a Bayesian approximation known as Monte Carlo dropout. In our example, we produce a national-scale probabilistic geochemical map from point-sampled assay data, with auxiliary information provided by a terrain elevation grid. Unlike traditional geostatistical approaches, auxiliary variable grids are fed into our deep neural network raw. There is no need to provide terrain derivatives (e.g. slope angles, roughness, etc) because the deep neural network is capable of learning these and arbitrarily more complex derivatives as necessary to maximise predictive performance. We hope our results will raise awareness of the suitability of Bayesian deep learning - and its feature learning capabilities - for large-scale geostatistical applications where uncertainty matters.