 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Compressed Regression
Paper and Code
Mar 22, 2013

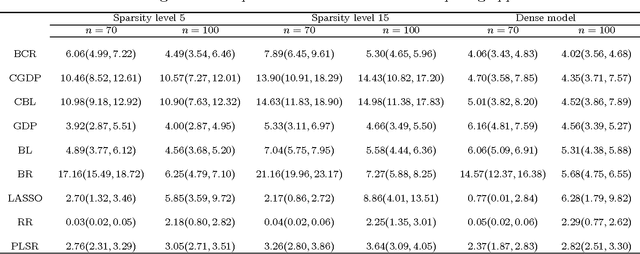
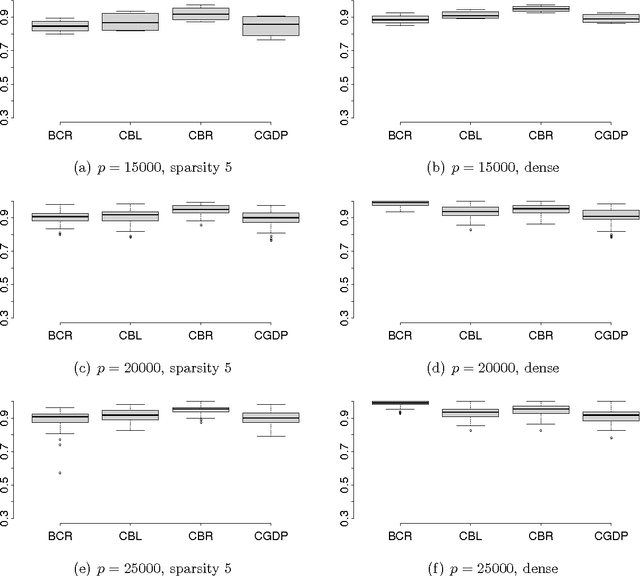
As an alternative to variable selection or shrinkage in high dimensional regression, we propose to randomly compress the predictors prior to analysis. This dramatically reduces storage and computational bottlenecks, performing well when the predictors can be projected to a low dimensional linear subspace with minimal loss of information about the response. As opposed to existing Bayesian dimensionality reduction approaches, the exact posterior distribution conditional on the compressed data is available analytically, speeding up computation by many orders of magnitude while also bypassing robustness issues due to convergence and mixing problems with MCMC. Model averaging is used to reduce sensitivity to the random projection matrix, while accommodating uncertainty in the subspace dimension. Strong theoretical support is provided for the approach by showing near parametric convergence rates for the predictive density in the large p small n asymptotic paradigm. Practical performance relative to competitors is illustrated in simulations and real data applications.