 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayes' Power for Explaining In-Context Learning Generalizations
Paper and Code
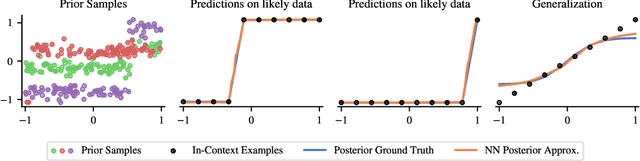
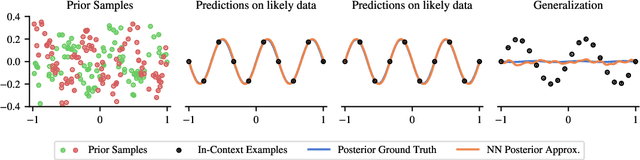
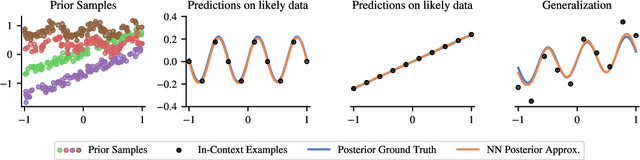
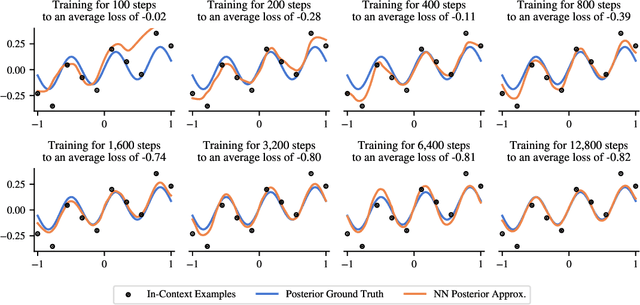
Traditionally, neural network training has been primarily viewed as an approximation of maximum likelihood estimation (MLE). This interpretation originated in a time when training for multiple epochs on small datasets was common and performance was data bound; but it falls short in the era of large-scale single-epoch trainings ushered in by large self-supervised setups, like language models. In this new setup, performance is compute-bound, but data is readily available. As models became more powerful, in-context learning (ICL), i.e., learning in a single forward-pass based on the context, emerged as one of the dominant paradigms. In this paper, we argue that a more useful interpretation of neural network behavior in this era is as an approximation of the true posterior, as defined by the data-generating process. We demonstrate this interpretations' power for ICL and its usefulness to predict generalizations to previously unseen tasks. We show how models become robust in-context learners by effectively composing knowledge from their training data. We illustrate this with experiments that reveal surprising generalizations, all explicable through the exact posterior. Finally, we show the inherent constraints of the generalization capabilities of posteriors and the limitations of neural networks in approximating these posteriors.