 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatched Lipschitz Bandits
Paper and Code

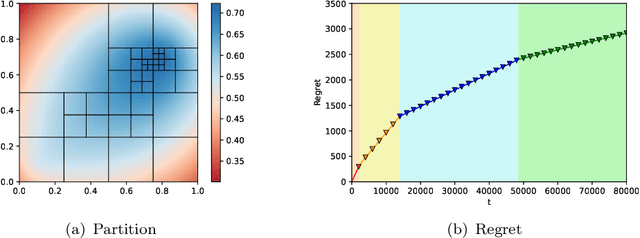
In this paper, we study the batched Lipschitz bandit problem, where the expected reward is Lipschitz and the reward observations are collected in batches. We introduce a novel landscape-aware algorithm, called Batched Lipschitz Narrowing (BLiN), that naturally fits into the batched feedback setting. In particular, we show that for a $T$-step problem with Lipschitz reward of zooming dimension $d_z$, our algorithm achieves theoretically optimal regret rate of $ \widetilde{\mathcal{O}} \left( T^{\frac{d_z + 1}{d_z + 2}} \right) $ using only $ \mathcal{O} \left( \frac{\log T}{d_z} \right) $ batches. For the lower bound, we show that in an environment with $B$-batches, for any policy $\pi$, there exists a problem instance such that the expected regret is lower bounded by $ \widetilde{\Omega} \left(R_z(T)^\frac{1}{1-\left(\frac{1}{d+2}\right)^B}\right) $, where $R_z (T)$ is the regret lower bound for vanilla Lipschitz bandits that depends on the zooming dimension $d_z$, and $d$ is the dimension of the arm space.