 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch-Expansion Training: An Efficient Optimization Framework
Paper and Code
Feb 23, 2018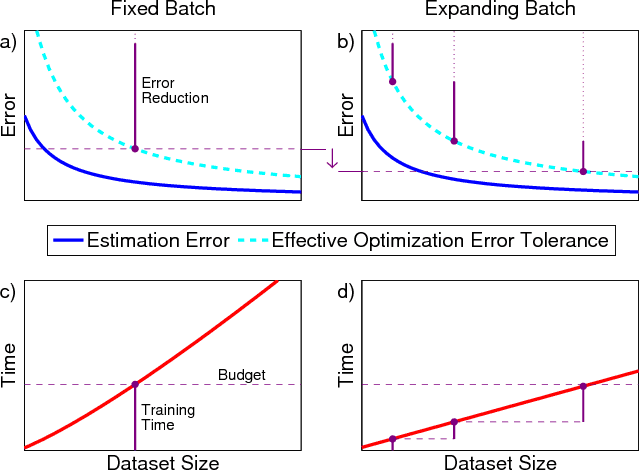
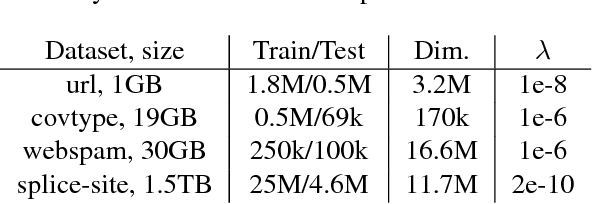
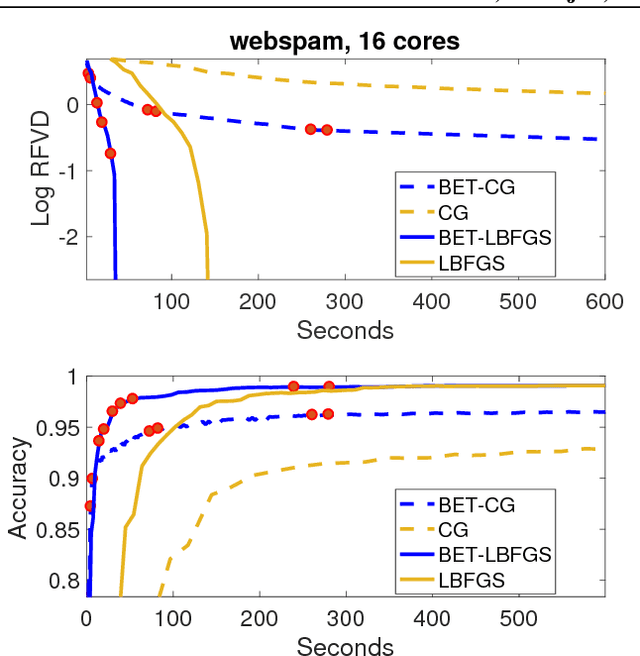
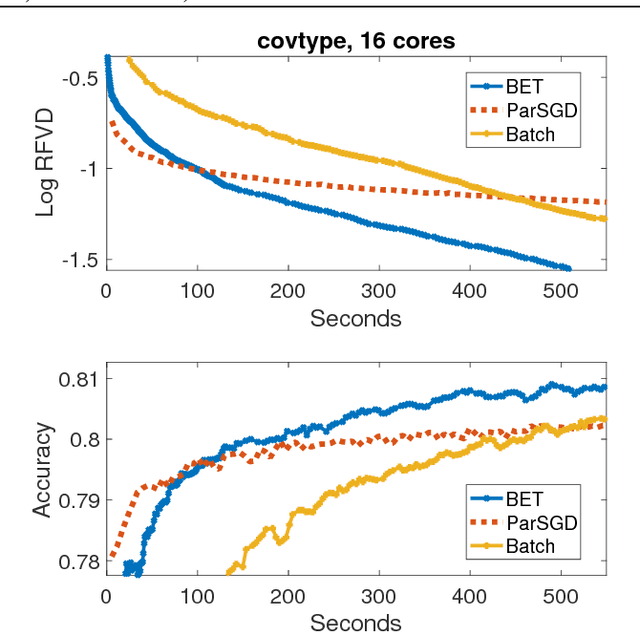
We propose Batch-Expansion Training (BET), a framework for running a batch optimizer on a gradually expanding dataset. As opposed to stochastic approaches, batches do not need to be resampled i.i.d. at every iteration, thus making BET more resource efficient in a distributed setting, and when disk-access is constrained. Moreover, BET can be easily paired with most batch optimizers, does not require any parameter-tuning, and compares favorably to existing stochastic and batch methods. We show that when the batch size grows exponentially with the number of outer iterations, BET achieves optimal $O(1/\epsilon)$ data-access convergence rate for strongly convex objectives. Experiments in parallel and distributed settings show that BET performs better than standard batch and stochastic approaches.