 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Curation for Unsupervised Contrastive Representation Learning
Paper and Code
Aug 19, 2021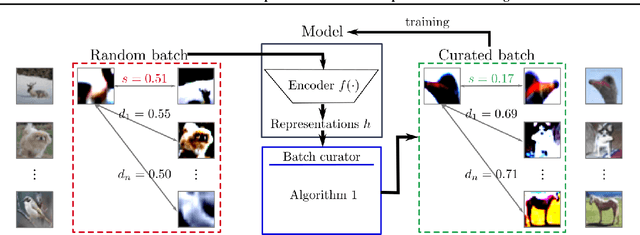


The state-of-the-art unsupervised contrastive visual representation learning methods that have emerged recently (SimCLR, MoCo, SwAV) all make use of data augmentations in order to construct a pretext task of instant discrimination consisting of similar and dissimilar pairs of images. Similar pairs are constructed by randomly extracting patches from the same image and applying several other transformations such as color jittering or blurring, while transformed patches from different image instances in a given batch are regarded as dissimilar pairs. We argue that this approach can result similar pairs that are \textit{semantically} dissimilar. In this work, we address this problem by introducing a \textit{batch curation} scheme that selects batches during the training process that are more inline with the underlying contrastive objective. We provide insights into what constitutes beneficial similar and dissimilar pairs as well as validate \textit{batch curation} on CIFAR10 by integrating it in the SimCLR model.