 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBasis Matters: Better Communication-Efficient Second Order Methods for Federated Learning
Paper and Code
Nov 02, 2021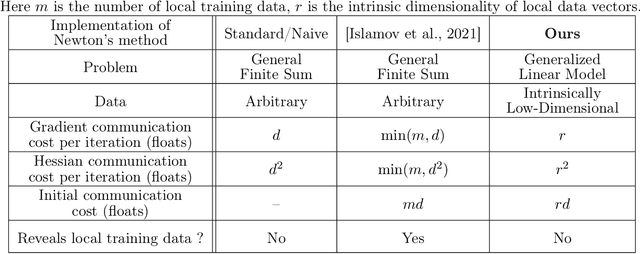



Recent advances in distributed optimization have shown that Newton-type methods with proper communication compression mechanisms can guarantee fast local rates and low communication cost compared to first order methods. We discover that the communication cost of these methods can be further reduced, sometimes dramatically so, with a surprisingly simple trick: {\em Basis Learn (BL)}. The idea is to transform the usual representation of the local Hessians via a change of basis in the space of matrices and apply compression tools to the new representation. To demonstrate the potential of using custom bases, we design a new Newton-type method (BL1), which reduces communication cost via both {\em BL} technique and bidirectional compression mechanism. Furthermore, we present two alternative extensions (BL2 and BL3) to partial participation to accommodate federated learning applications. We prove local linear and superlinear rates independent of the condition number. Finally, we support our claims with numerical experiments by comparing several first and second~order~methods.