 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Privacy Protection and Interpretability in Federated Learning
Paper and Code
Feb 16, 2023


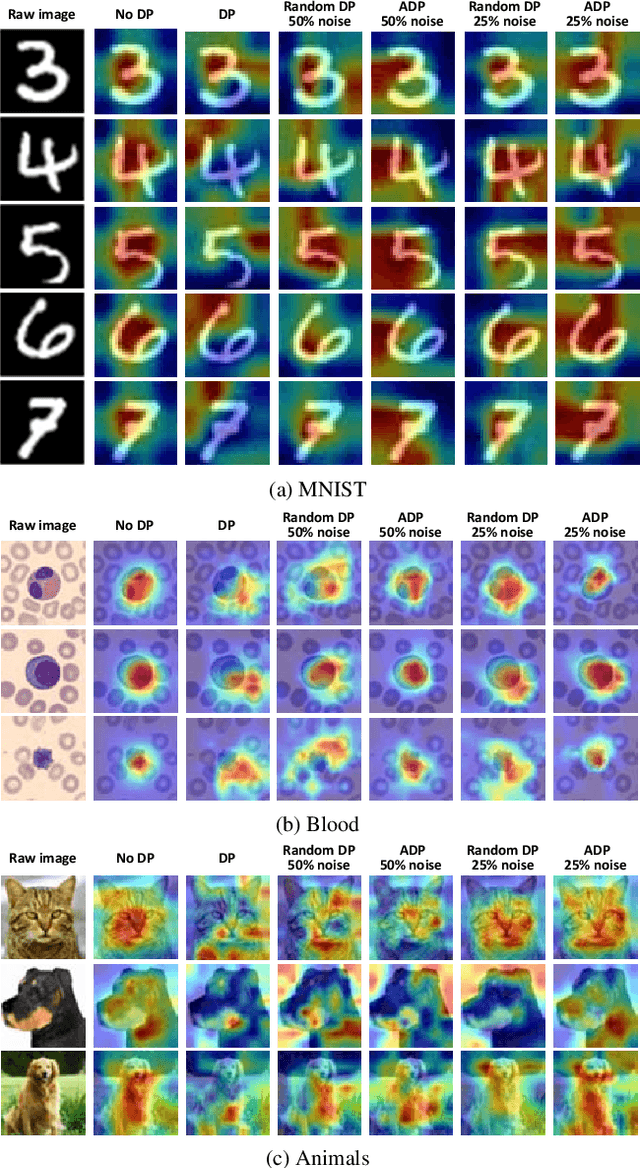
Federated learning (FL) aims to collaboratively train the global model in a distributed manner by sharing the model parameters from local clients to a central server, thereby potentially protecting users' private information. Nevertheless, recent studies have illustrated that FL still suffers from information leakage as adversaries try to recover the training data by analyzing shared parameters from local clients. To deal with this issue, differential privacy (DP) is adopted to add noise to the gradients of local models before aggregation. It, however, results in the poor performance of gradient-based interpretability methods, since some weights capturing the salient region in feature map will be perturbed. To overcome this problem, we propose a simple yet effective adaptive differential privacy (ADP) mechanism that selectively adds noisy perturbations to the gradients of client models in FL. We also theoretically analyze the impact of gradient perturbation on the model interpretability. Finally, extensive experiments on both IID and Non-IID data demonstrate that the proposed ADP can achieve a good trade-off between privacy and interpretability in FL.