 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBadDet: Backdoor Attacks on Object Detection
Paper and Code
May 28, 2022
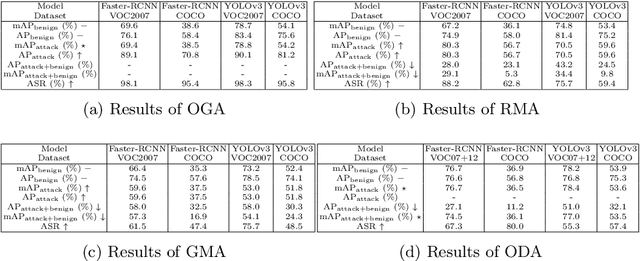


Deep learning models have been deployed in numerous real-world applications such as autonomous driving and surveillance. However, these models are vulnerable in adversarial environments. Backdoor attack is emerging as a severe security threat which injects a backdoor trigger into a small portion of training data such that the trained model behaves normally on benign inputs but gives incorrect predictions when the specific trigger appears. While most research in backdoor attacks focuses on image classification, backdoor attacks on object detection have not been explored but are of equal importance. Object detection has been adopted as an important module in various security-sensitive applications such as autonomous driving. Therefore, backdoor attacks on object detection could pose severe threats to human lives and properties. We propose four kinds of backdoor attacks for object detection task: 1) Object Generation Attack: a trigger can falsely generate an object of the target class; 2) Regional Misclassification Attack: a trigger can change the prediction of a surrounding object to the target class; 3) Global Misclassification Attack: a single trigger can change the predictions of all objects in an image to the target class; and 4) Object Disappearance Attack: a trigger can make the detector fail to detect the object of the target class. We develop appropriate metrics to evaluate the four backdoor attacks on object detection. We perform experiments using two typical object detection models -- Faster-RCNN and YOLOv3 on different datasets. More crucially, we demonstrate that even fine-tuning on another benign dataset cannot remove the backdoor hidden in the object detection model. To defend against these backdoor attacks, we propose Detector Cleanse, an entropy-based run-time detection framework to identify poisoned testing samples for any deployed object detector.