 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBacktesting the predictability of COVID-19
Paper and Code
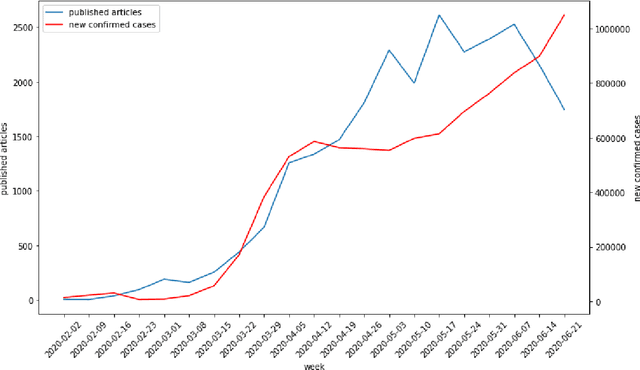

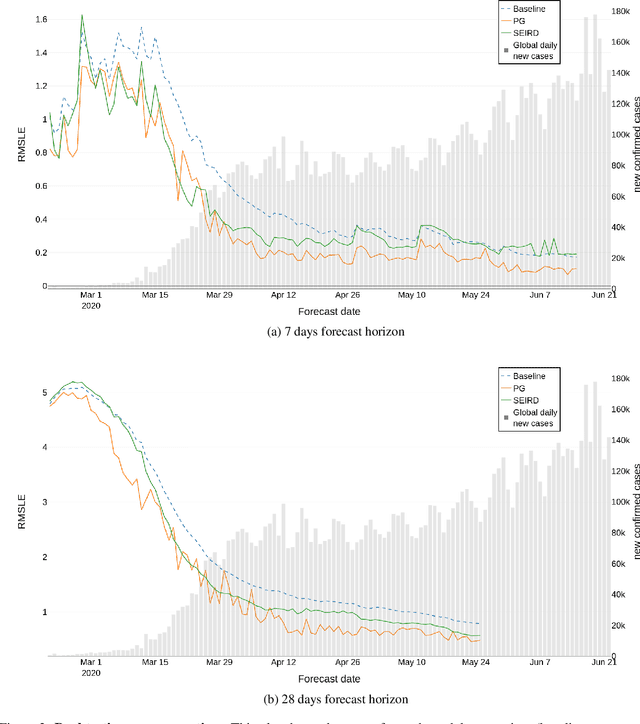
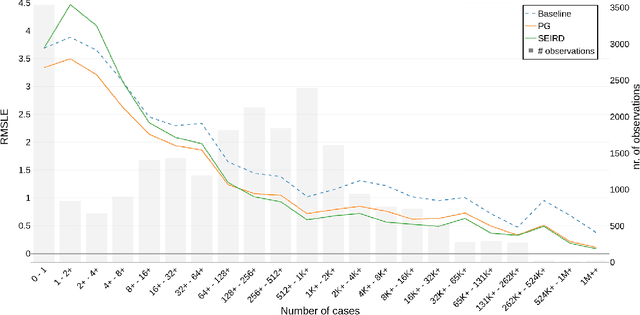
The advent of the COVID-19 pandemic has instigated unprecedented changes in many countries around the globe, putting a significant burden on the health sectors, affecting the macro economic conditions, and altering social interactions amongst the population. In response, the academic community has produced multiple forecasting models, approaches and algorithms to best predict the different indicators of COVID-19, such as the number of confirmed infected cases. Yet, researchers had little to no historical information about the pandemic at their disposal in order to inform their forecasting methods. Our work studies the predictive performance of models at various stages of the pandemic to better understand their fundamental uncertainty and the impact of data availability on such forecasts. We use historical data of COVID-19 infections from 253 regions from the period of 22nd January 2020 until 22nd June 2020 to predict, through a rolling window backtesting framework, the cumulative number of infected cases for the next 7 and 28 days. We implement three simple models to track the root mean squared logarithmic error in this 6-month span, a baseline model that always predicts the last known value of the cumulative confirmed cases, a power growth model and an epidemiological model called SEIRD. Prediction errors are substantially higher in early stages of the pandemic, resulting from limited data. Throughout the course of the pandemic, errors regress slowly, but steadily. The more confirmed cases a country exhibits at any point in time, the lower the error in forecasting future confirmed cases. We emphasize the significance of having a rigorous backtesting framework to accurately assess the predictive power of such models at any point in time during the outbreak which in turn can be used to assign the right level of certainty to these forecasts and facilitate better planning.