 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Attacks on Network Certification via Data Poisoning
Paper and Code
Aug 25, 2021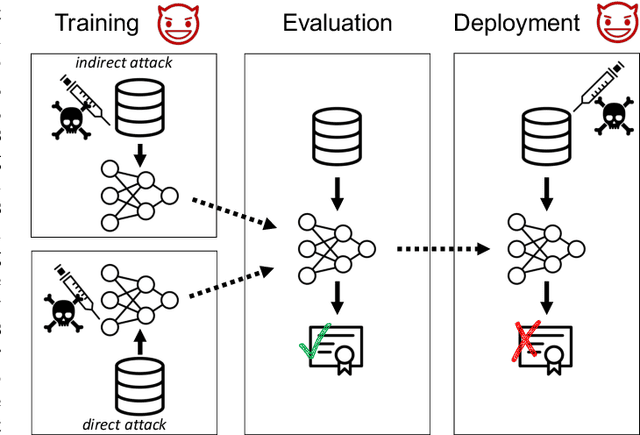

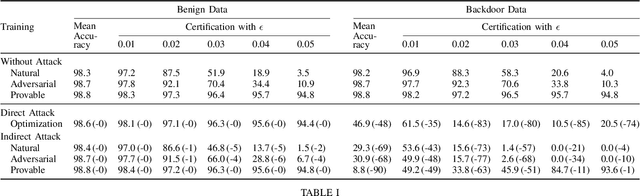

Certifiers for neural networks have made great progress towards provable robustness guarantees against evasion attacks using adversarial examples. However, introducing certifiers into deep learning systems also opens up new attack vectors, which need to be considered before deployment. In this work, we conduct the first systematic analysis of training time attacks against certifiers in practical application pipelines, identifying new threat vectors that can be exploited to degrade the overall system. Using these insights, we design two backdoor attacks against network certifiers, which can drastically reduce certified robustness when the backdoor is activated. For example, adding 1% poisoned data points during training is sufficient to reduce certified robustness by up to 95 percentage points, effectively rendering the certifier useless. We analyze how such novel attacks can compromise the overall system's integrity or availability. Our extensive experiments across multiple datasets, model architectures, and certifiers demonstrate the wide applicability of these attacks. A first investigation into potential defenses shows that current approaches only partially mitigate the issue, highlighting the need for new, more specific solutions.