 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to Basics: Benchmarking Canonical Evolution Strategies for Playing Atari
Paper and Code
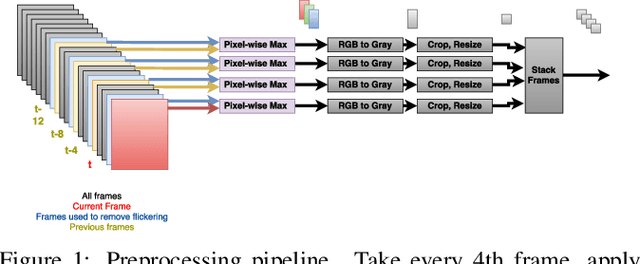
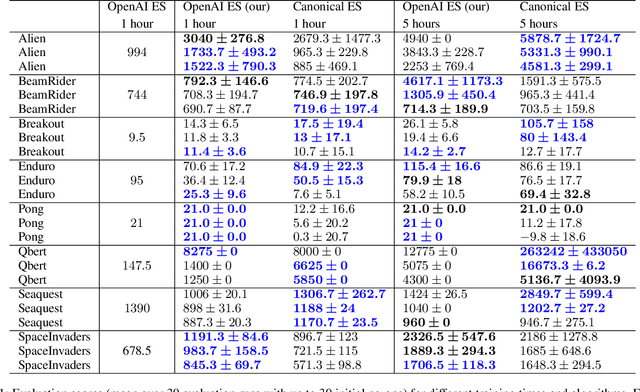

Evolution Strategies (ES) have recently been demonstrated to be a viable alternative to reinforcement learning (RL) algorithms on a set of challenging deep RL problems, including Atari games and MuJoCo humanoid locomotion benchmarks. While the ES algorithms in that work belonged to the specialized class of natural evolution strategies (which resemble approximate gradient RL algorithms, such as REINFORCE), we demonstrate that even a very basic canonical ES algorithm can achieve the same or even better performance. This success of a basic ES algorithm suggests that the state-of-the-art can be advanced further by integrating the many advances made in the field of ES in the last decades. We also demonstrate qualitatively that ES algorithms have very different performance characteristics than traditional RL algorithms: on some games, they learn to exploit the environment and perform much better while on others they can get stuck in suboptimal local minima. Combining their strengths with those of traditional RL algorithms is therefore likely to lead to new advances in the state of the art.