 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Classification of Pathology Reports using TF-IDF Features
Paper and Code
Mar 05, 2019


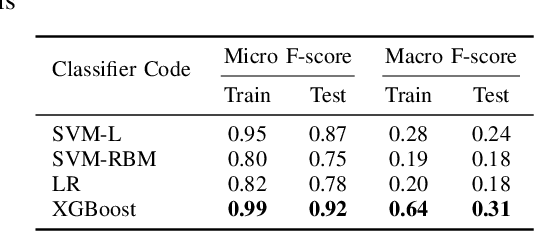
A Pathology report is arguably one of the most important documents in medicine containing interpretive information about the visual findings from the patient's biopsy sample. Each pathology report has a retention period of up to 20 years after the treatment of a patient. Cancer registries process and encode high volumes of free-text pathology reports for surveillance of cancer and tumor diseases all across the world. In spite of their extremely valuable information they hold, pathology reports are not used in any systematic way to facilitate computational pathology. Therefore, in this study, we investigate automated machine-learning techniques to identify/predict the primary diagnosis (based on ICD-O code) from pathology reports. We performed experiments by extracting the TF-IDF features from the reports and classifying them using three different methods---SVM, XGBoost, and Logistic Regression. We constructed a new dataset with 1,949 pathology reports arranged into 37 ICD-O categories, collected from four different primary sites, namely lung, kidney, thymus, and testis. The reports were manually transcribed into text format after collecting them as PDF files from NCI Genomic Data Commons public dataset. We subsequently pre-processed the reports by removing irrelevant textual artifacts produced by OCR software. The highest classification accuracy we achieved was 92\% using XGBoost classifier on TF-IDF feature vectors, the linear SVM scored 87\% accuracy. Furthermore, the study shows that TF-IDF vectors are suitable for highlighting the important keywords within a report which can be helpful for the cancer research and diagnostic workflow. The results are encouraging in demonstrating the potential of machine learning methods for classification and encoding of pathology reports.