Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Vectorizing TensorFlow Graphs: Jacobians, Auto-Batching And Beyond
Paper and Code
Mar 08, 2019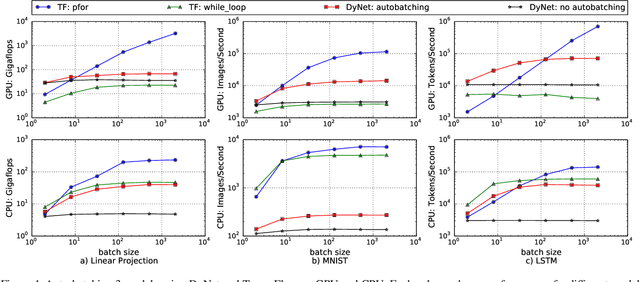
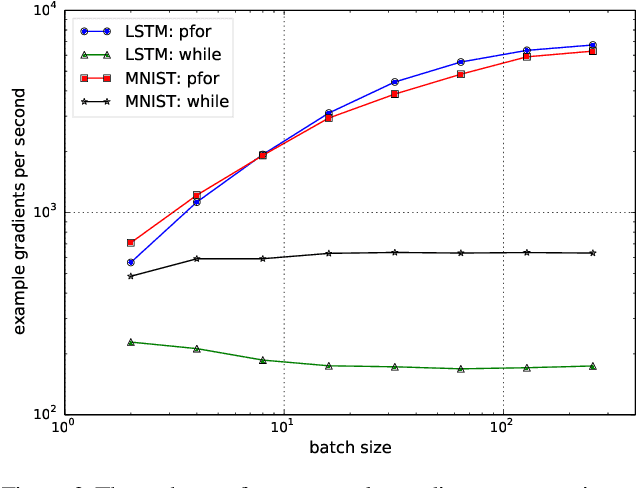
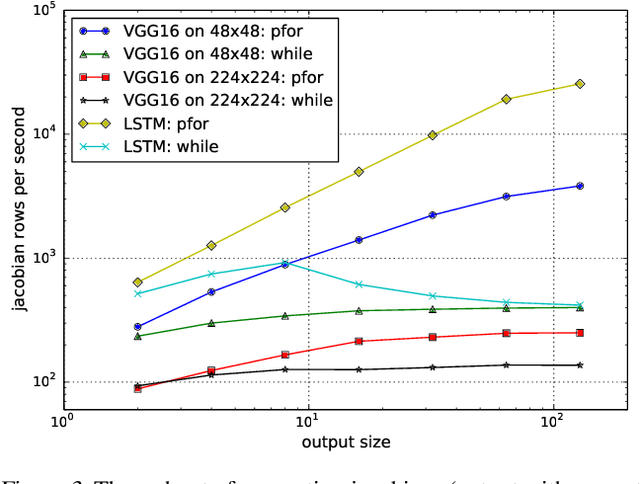
We propose a static loop vectorization optimization on top of high level dataflow IR used by frameworks like TensorFlow. A new statically vectorized parallel-for abstraction is provided on top of TensorFlow, and used for applications ranging from auto-batching and per-example gradients, to jacobian computation, optimized map functions and input pipeline optimization. We report huge speedups compared to both loop based implementations, as well as run-time batching adopted by the DyNet framework.
View paper on