 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-PyTorch Tabular: Multi-Fidelity MetaLearning for Efficient and Robust AutoDL
Paper and Code
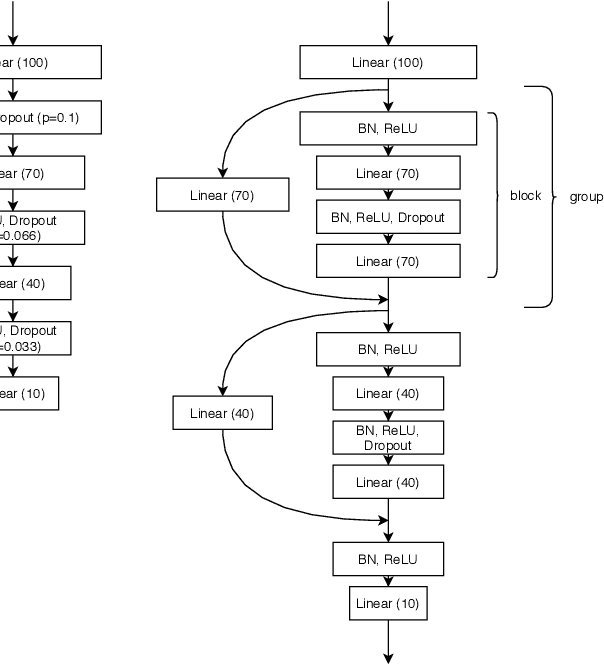
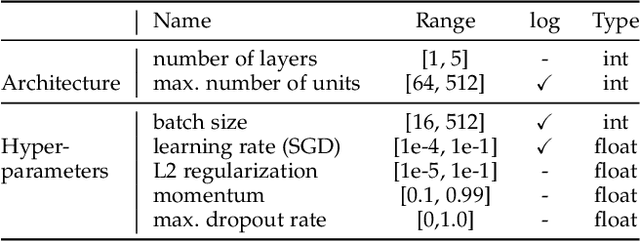

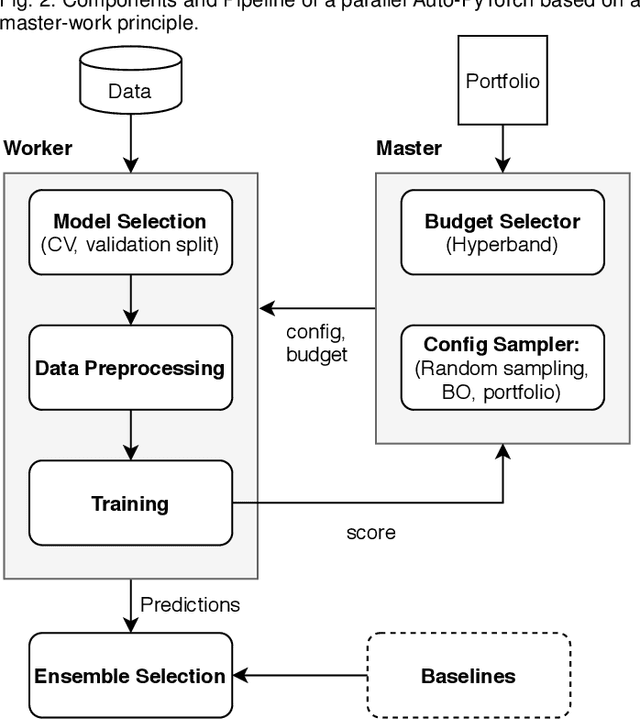
While early AutoML frameworks focused on optimizing traditional ML pipelines and their hyperparameters, a recent trend in AutoML is to focus on neural architecture search. In this paper, we introduce Auto-PyTorch, which brings the best of these two worlds together by jointly and robustly optimizing the architecture of networks and the training hyperparameters to enable fully automated deep learning (AutoDL). Auto-PyTorch achieves state-of-the-art performance on several tabular benchmarks by combining multi-fidelity optimization with portfolio construction for warmstarting and ensembling of deep neural networks (DNNs) and common baselines for tabular data. To thoroughly study our assumptions on how to design such an AutoDL system, we additionally introduce a new benchmark on learning curves for DNNs, dubbed LCBench, and run extensive ablation studies of the full Auto-PyTorch on typical AutoML benchmarks, eventually showing that Auto-PyTorch performs better than several state-of-the-art competitors on average.