 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-captions on GIF: A Large-scale Video-sentence Dataset for Vision-language Pre-training
Paper and Code

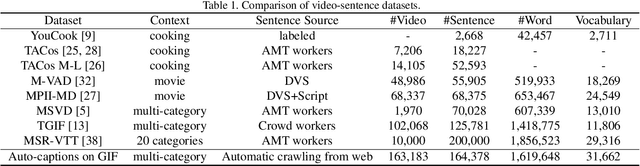
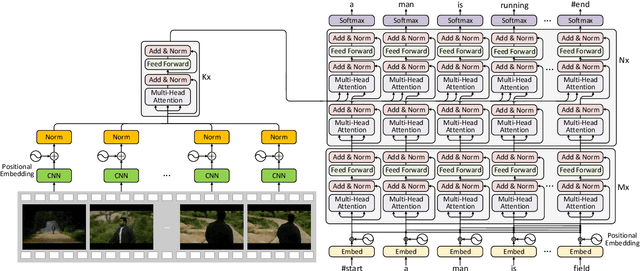
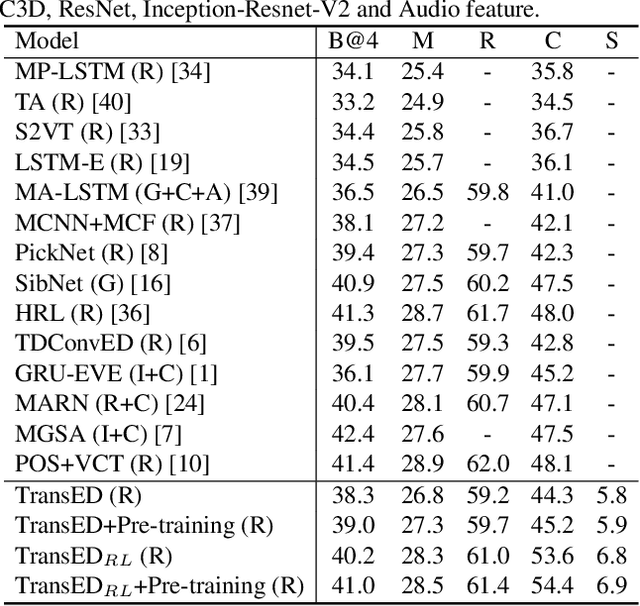
In this work, we present Auto-captions on GIF, which is a new large-scale pre-training dataset for generic video understanding. All video-sentence pairs are created by automatically extracting and filtering video caption annotations from billions of web pages. Auto-captions on GIF dataset can be utilized to pre-train the generic feature representation or encoder-decoder structure for video captioning, and other downstream tasks (e.g., sentence localization in videos, video question answering, etc.) as well. We present a detailed analysis of Auto-captions on GIF dataset in comparison to existing video-sentence datasets. We also provide an evaluation of a Transformer-based encoder-decoder structure for vision-language pre-training, which is further adapted to video captioning downstream task and yields the compelling generalizability on MSR-VTT. The dataset is available at \url{http://www.auto-video-captions.top/2020/dataset}.