 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute-Induced Bias Eliminating for Transductive Zero-Shot Learning
Paper and Code
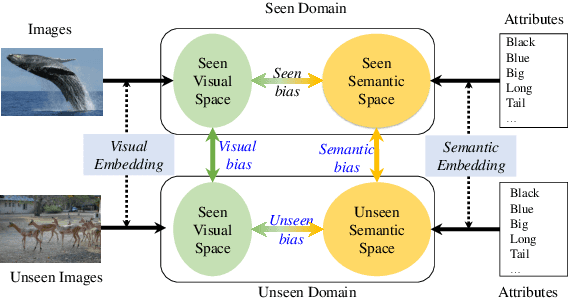
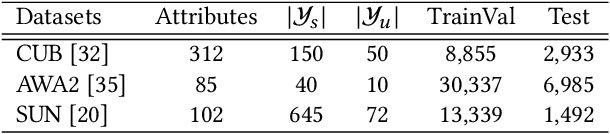
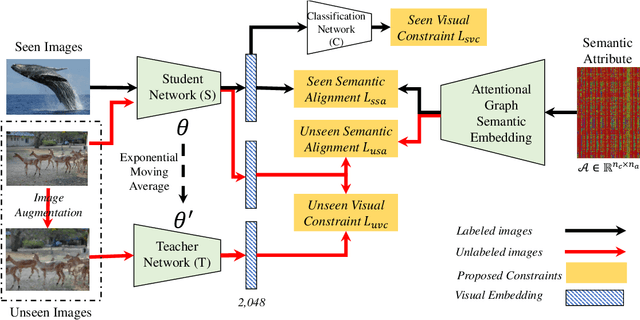
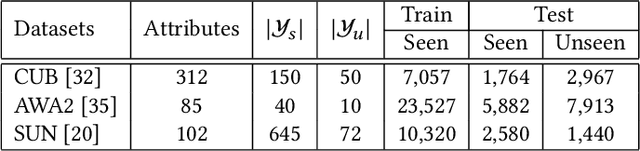
Transductive Zero-shot learning (ZSL) targets to recognize the unseen categories by aligning the visual and semantic information in a joint embedding space. There exist four kinds of domain biases in Transductive ZSL, i.e., visual bias and semantic bias between two domains and two visual-semantic biases in respective seen and unseen domains, but existing work only focuses on the part of them, which leads to severe semantic ambiguity during the knowledge transfer. To solve the above problem, we propose a novel Attribute-Induced Bias Eliminating (AIBE) module for Transductive ZSL. Specifically, for the visual bias between two domains, the Mean-Teacher module is first leveraged to bridge the visual representation discrepancy between two domains with unsupervised learning and unlabelled images. Then, an attentional graph attribute embedding is proposed to reduce the semantic bias between seen and unseen categories, which utilizes the graph operation to capture the semantic relationship between categories. Besides, to reduce the semantic-visual bias in the seen domain, we align the visual center of each category, instead of the individual visual data point, with the corresponding semantic attributes, which further preserves the semantic relationship in the embedding space. Finally, for the semantic-visual bias in the unseen domain, an unseen semantic alignment constraint is designed to align visual and semantic space in an unsupervised manner. The evaluations on several benchmarks demonstrate the effectiveness of the proposed method, e.g., obtaining the 82.8%/75.5%, 97.1%/82.5%, and 73.2%/52.1% for Conventional/Generalized ZSL settings for CUB, AwA2, and SUN datasets, respectively.