 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttraction-Based Receding Horizon Path Planning with Temporal Logic Constraints
Paper and Code
Aug 29, 2012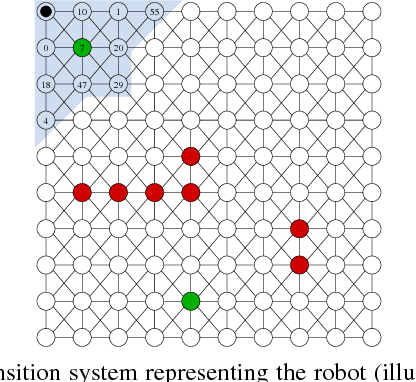
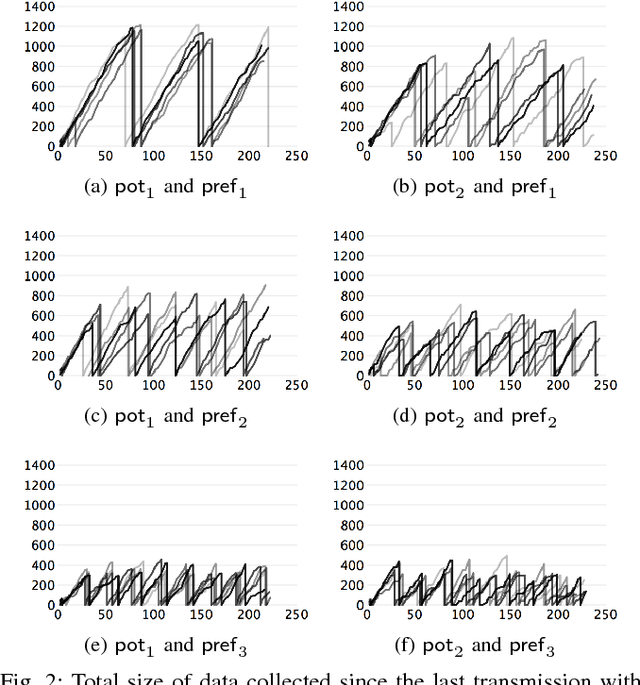

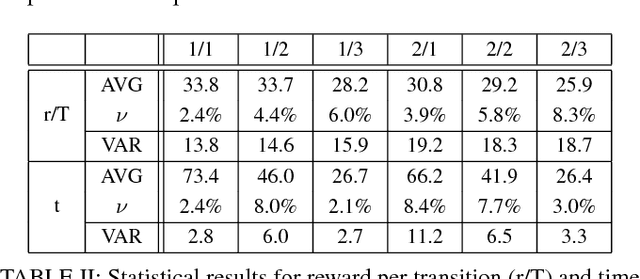
Our goal in this paper is to plan the motion of a robot in a partitioned environment with dynamically changing, locally sensed rewards. We assume that arbitrary assumptions on the reward dynamics can be given. The robot aims to accomplish a high-level temporal logic surveillance mission and to locally optimize the collection of the rewards in the visited regions. These two objectives often conflict and only a compromise between them can be reached. We address this issue by taking into consideration a user-defined preference function that captures the trade-off between the importance of collecting high rewards and the importance of making progress towards a surveyed region. Our solution leverages ideas from the automata-based approach to model checking. We demonstrate the utilization and benefits of the suggested framework in an illustrative example.