 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-guided Generative Models for Extractive Question Answering
Paper and Code

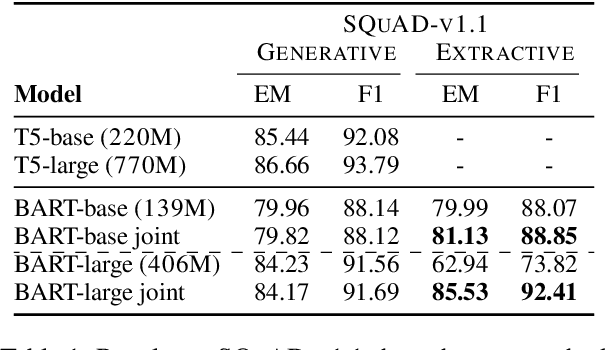
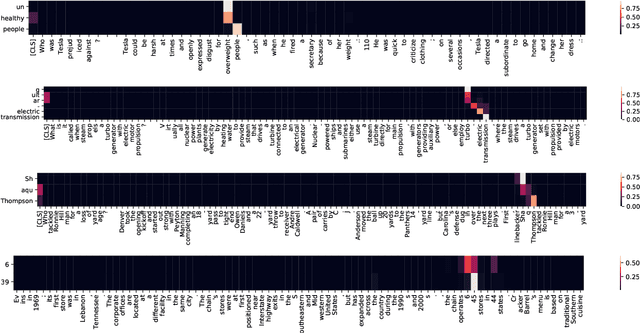
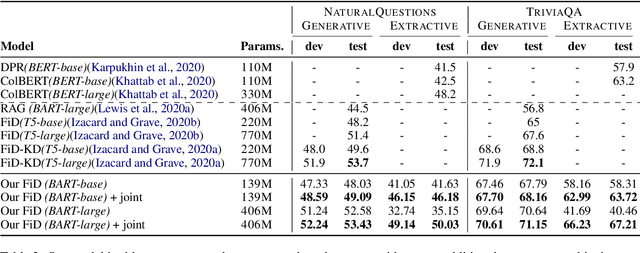
We propose a novel method for applying Transformer models to extractive question answering (QA) tasks. Recently, pretrained generative sequence-to-sequence (seq2seq) models have achieved great success in question answering. Contributing to the success of these models are internal attention mechanisms such as cross-attention. We propose a simple strategy to obtain an extractive answer span from the generative model by leveraging the decoder cross-attention patterns. Viewing cross-attention as an architectural prior, we apply joint training to further improve QA performance. Empirical results show that on open-domain question answering datasets like NaturalQuestions and TriviaQA, our method approaches state-of-the-art performance on both generative and extractive inference, all while using much fewer parameters. Furthermore, this strategy allows us to perform hallucination-free inference while conferring significant improvements to the model's ability to rerank relevant passages.