 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttending Category Disentangled Global Context for Image Classification
Paper and Code
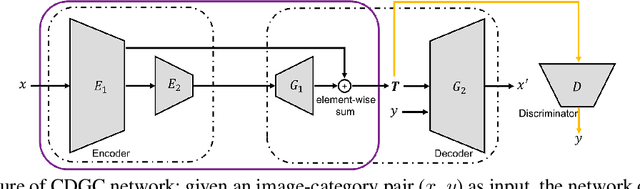
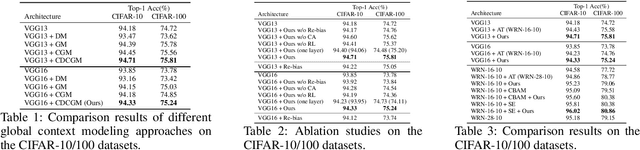
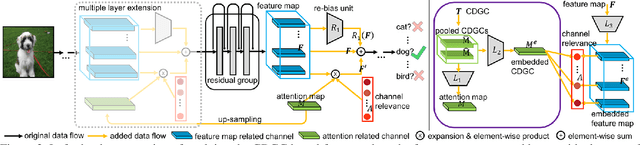
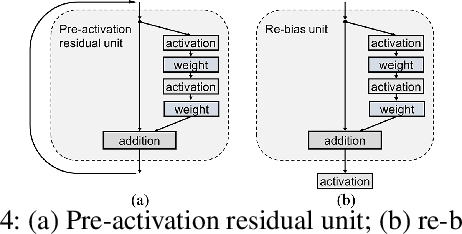
In this paper, we propose a general framework for image classification using the attention mechanism and global context, which could incorporate with various network architectures to improve their performance. To investigate the capability of the global context, we compare four mathematical models and observe the global context encoded in the category disentangled conditional generative model retains the richest complementary information to that in the baseline classification networks. Based on this observation, we define a novel Category Disentangled Global Context (CDGC) and devise a deep network to obtain it. By attending CDGC, the baseline networks could identify the objects of interest more accurately, thus improving the performance. We apply the framework to many different network architectures to demonstrate its effectiveness and versatility. Extensive results on four publicly available datasets validate our approach could generalize well and is superior to the state-of-the-art. In addition, the framework could be combined with various self-attention based methods to further promote the performance. Code and pretrained models will be made public upon paper acceptance.