 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Edge Learning using Cloned Knowledge Distillation
Paper and Code
Oct 22, 2020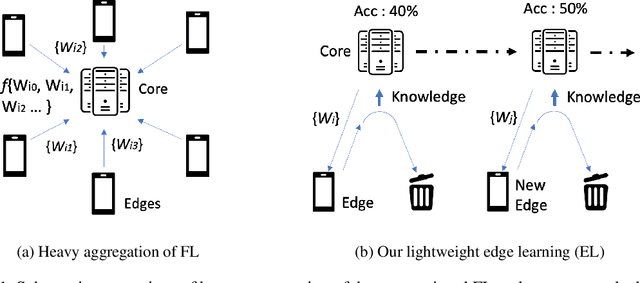
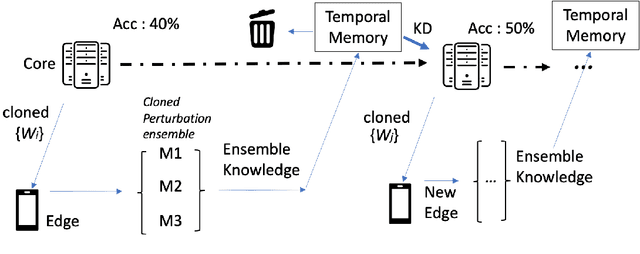
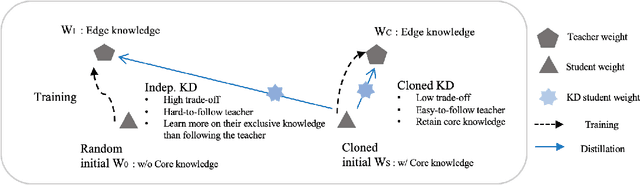
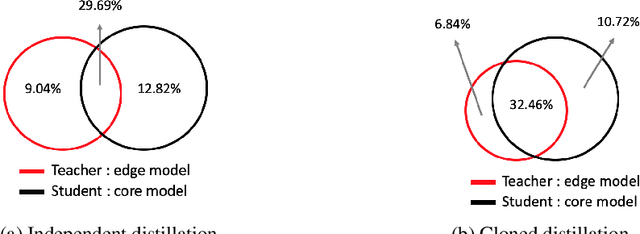
With the increasing demand for more and more data, the federated learning (FL) methods, which try to utilize highly distributed on-device local data in the training process, have been proposed.However, fledgling services provided by startup companies not only have limited number of clients, but also have minimal resources for constant communications between the server and multiple clients. In addition, in a real-world environment where the user pool changes dynamically, the FL system must be able to efficiently utilize rapid inflow and outflow of users, while at the same time experience minimal bottleneck due to network delays of multiple users. In this respect, we amend the federated learning scenario to a more flexible asynchronous edge learning. To solve the aforementioned learning problems, we propose an asynchronous model-based communication method with knowledge distillation. In particular, we dub our knowledge distillation scheme as "cloned distillation" and explain how it is different from other knowledge distillation method. In brief, we found that in knowledge distillation between the teacher and the student there exist two contesting traits in the student: to attend to the teacher's knowledge or to retain its own knowledge exclusive to the teacher. And in this edge learning scenario, the attending property should be amplified rather than the retaining property, because teachers are dispatched to the users to learn from them and recollected at the server to teach the core model. Our asynchronous edge learning method can elastically handle the dynamic inflow and outflow of users in a service with minimal communication cost, operate with essentially no bottleneck due to user delay, and protect user's privacy. Also we found that it is robust to users who behave abnormally or maliciously.