 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymptotic optimality and minimal complexity of classification by random projection
Paper and Code
Aug 11, 2021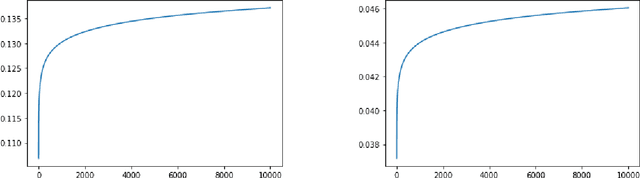
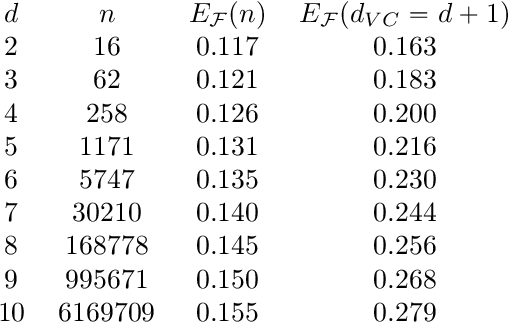
The generalization error of a classifier is related to the complexity of the set of functions among which the classifier is chosen. Roughly speaking, the more complex the family, the greater the potential disparity between the training error and the population error of the classifier. This principle is embodied in layman's terms by Occam's razor principle, which suggests favoring low-complexity hypotheses over complex ones. We study a family of low-complexity classifiers consisting of thresholding the one-dimensional feature obtained by projecting the data on a random line after embedding it into a higher dimensional space parametrized by monomials of order up to k. More specifically, the extended data is projected n-times and the best classifier among those n (based on its performance on training data) is chosen. We obtain a bound on the generalization error of these low-complexity classifiers. The bound is less than that of any classifier with a non-trivial VC dimension, and thus less than that of a linear classifier. We also show that, given full knowledge of the class conditional densities, the error of the classifiers would converge to the optimal (Bayes) error as k and n go to infinity; if only a training dataset is given, we show that the classifiers will perfectly classify all the training points as k and n go to infinity.