 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssured RL: Reinforcement Learning with Almost Sure Constraints
Paper and Code
Dec 24, 2020
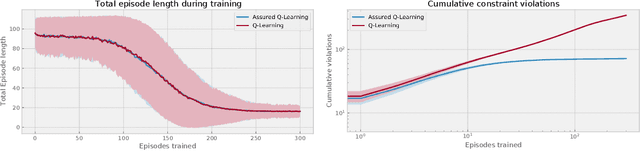
We consider the problem of finding optimal policies for a Markov Decision Process with almost sure constraints on state transitions and action triplets. We define value and action-value functions that satisfy a barrier-based decomposition which allows for the identification of feasible policies independently of the reward process. We prove that, given a policy {\pi}, certifying whether certain state-action pairs lead to feasible trajectories under {\pi} is equivalent to solving an auxiliary problem aimed at finding the probability of performing an unfeasible transition. Using this interpretation,we develop a Barrier-learning algorithm, based on Q-Learning, that identifies such unsafe state-action pairs. Our analysis motivates the need to enhance the Reinforcement Learning (RL) framework with an additional signal, besides rewards, called here damage function that provides feasibility information and enables the solution of RL problems with model-free constraints. Moreover, our Barrier-learning algorithm wraps around existing RL algorithms, such as Q-Learning and SARSA, giving them the ability to solve almost-surely constrained problems.