 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the trade-off between prediction accuracy and interpretability for topic modeling on energetic materials corpora
Paper and Code
Jun 01, 2022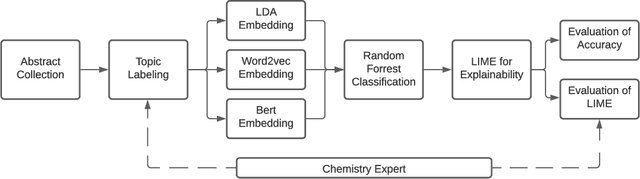
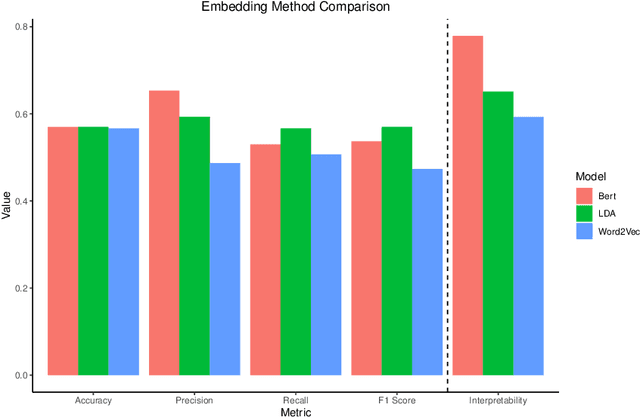

As the amount and variety of energetics research increases, machine aware topic identification is necessary to streamline future research pipelines. The makeup of an automatic topic identification process consists of creating document representations and performing classification. However, the implementation of these processes on energetics research imposes new challenges. Energetics datasets contain many scientific terms that are necessary to understand the context of a document but may require more complex document representations. Secondly, the predictions from classification must be understandable and trusted by the chemists within the pipeline. In this work, we study the trade-off between prediction accuracy and interpretability by implementing three document embedding methods that vary in computational complexity. With our accuracy results, we also introduce local interpretability model-agnostic explanations (LIME) of each prediction to provide a localized understanding of each prediction and to validate classifier decisions with our team of energetics experts. This study was carried out on a novel labeled energetics dataset created and validated by our team of energetics experts.