 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Human Likeness of AI-Generated Counterspeech
Paper and Code
Oct 14, 2024
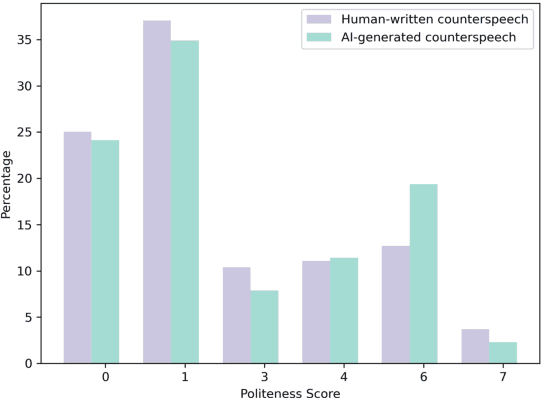
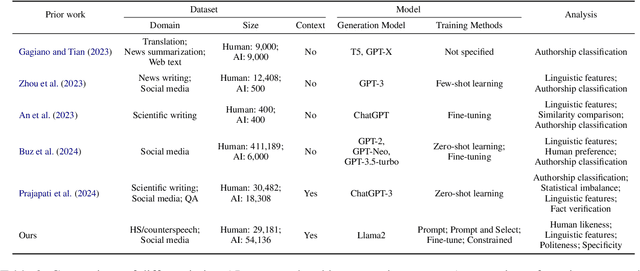
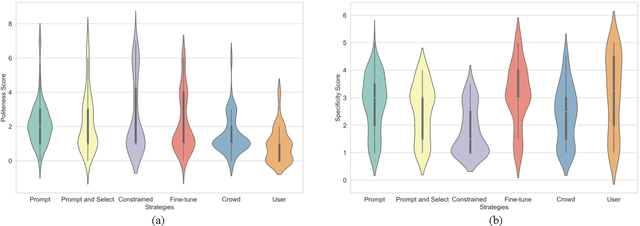
Counterspeech is a targeted response to counteract and challenge abusive or hateful content. It can effectively curb the spread of hatred and foster constructive online communication. Previous studies have proposed different strategies for automatically generated counterspeech. Evaluations, however, focus on the relevance, surface form, and other shallow linguistic characteristics. In this paper, we investigate the human likeness of AI-generated counterspeech, a critical factor influencing effectiveness. We implement and evaluate several LLM-based generation strategies, and discover that AI-generated and human-written counterspeech can be easily distinguished by both simple classifiers and humans. Further, we reveal differences in linguistic characteristics, politeness, and specificity.