 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Effectiveness of Syntactic Structure to Learn Code Edit Representations
Paper and Code
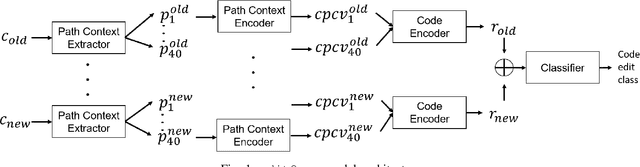
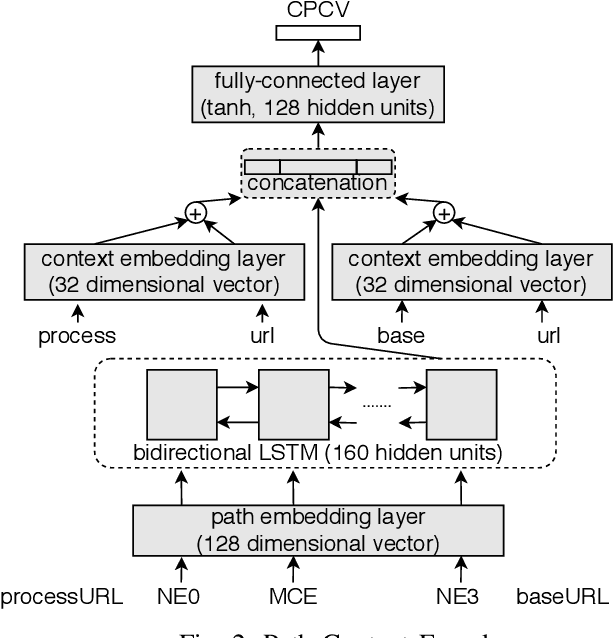
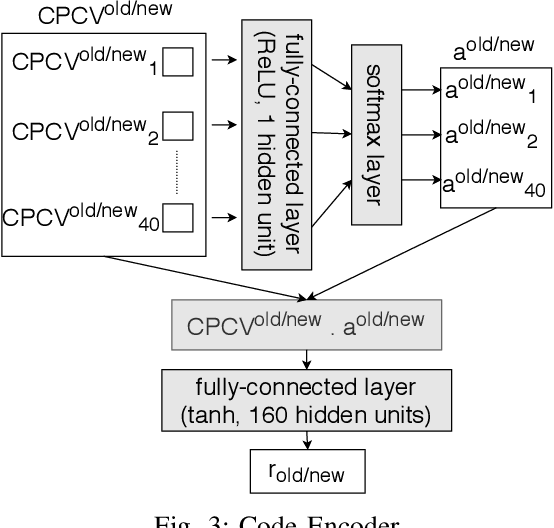
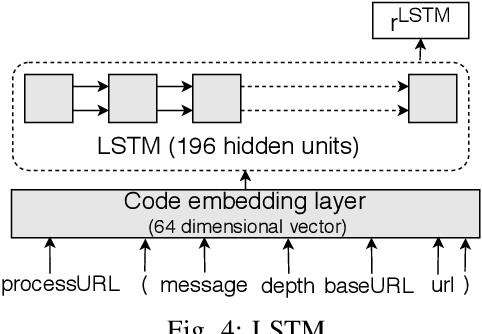
In recent times, it has been shown that one can use code as data to aid various applications such as automatic commit message generation, automatic generation of pull request descriptions and automatic program repair. Take for instance the problem of commit message generation. Treating source code as a sequence of tokens, state of the art techniques generate commit messages using neural machine translation models. However, they tend to ignore the syntactic structure of programming languages. Previous work, i.e., code2seq has used structural information from Abstract Syntax Tree (AST) to represent source code and they use it to automatically generate method names. In this paper, we elaborate upon this state of the art approach and modify it to represent source code edits. We determine the effect of using such syntactic structure for the problem of classifying code edits. Inspired by the code2seq approach, we evaluate how using structural information from AST, i.e., paths between AST leaf nodes can help with the task of code edit classification on two datasets of fine-grained syntactic edits. Our experiments shows that attempts of adding syntactic structure does not result in any improvements over less sophisticated methods. The results suggest that techniques such as code2seq, while promising, have a long way to go before they can be generically applied to learning code edit representations. We hope that these results will benefit other researchers and inspire them to work further on this problem.