 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsk-n-Learn: Active Learning via Reliable Gradient Representations for Image Classification
Paper and Code
Sep 30, 2020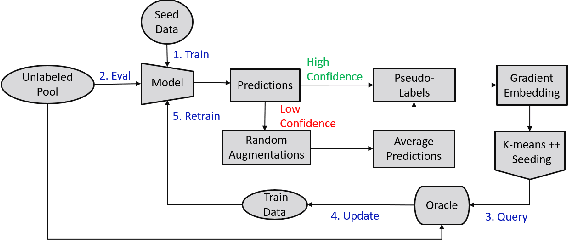
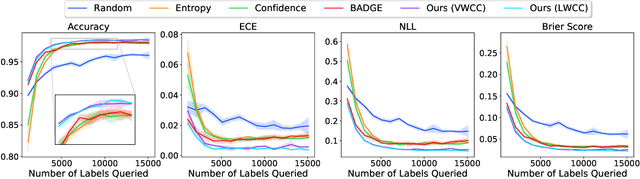
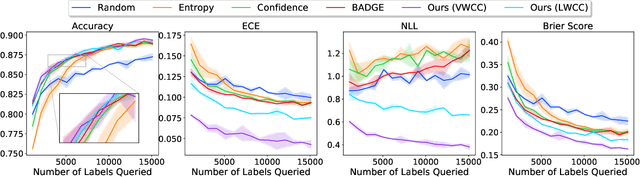
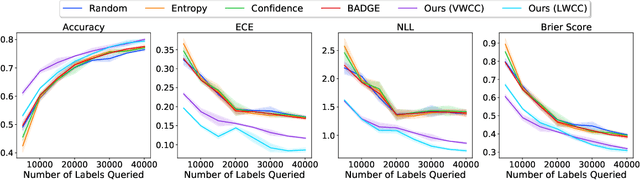
Deep predictive models rely on human supervision in the form of labeled training data. Obtaining large amounts of annotated training data can be expensive and time consuming, and this becomes a critical bottleneck while building such models in practice. In such scenarios, active learning (AL) strategies are used to achieve faster convergence in terms of labeling efforts. Existing active learning employ a variety of heuristics based on uncertainty and diversity to select query samples. Despite their wide-spread use, in practice, their performance is limited by a number of factors including non-calibrated uncertainties, insufficient trade-off between data exploration and exploitation, presence of confirmation bias etc. In order to address these challenges, we propose Ask-n-Learn, an active learning approach based on gradient embeddings obtained using the pesudo-labels estimated in each iteration of the algorithm. More importantly, we advocate the use of prediction calibration to obtain reliable gradient embeddings, and propose a data augmentation strategy to alleviate the effects of confirmation bias during pseudo-labeling. Through empirical studies on benchmark image classification tasks (CIFAR-10, SVHN, Fashion-MNIST, MNIST), we demonstrate significant improvements over state-of-the-art baselines, including the recently proposed BADGE algorithm.