 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable Misinformation Mitigation: Generalization, Uncertainty, and GPT-4
Paper and Code
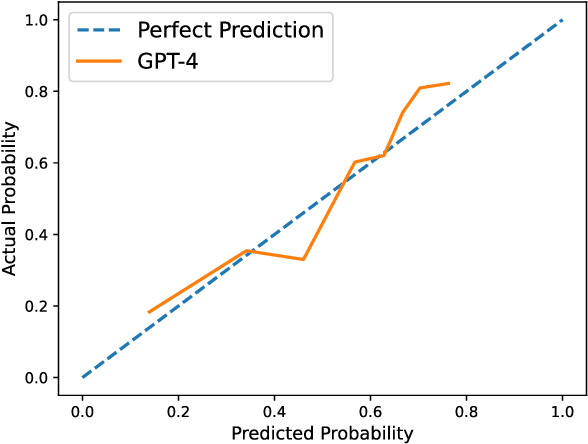



Misinformation poses a critical societal challenge, and current approaches have yet to produce an effective solution. We propose focusing on generalization, soft classification, and leveraging recent large language models to create more practical tools in contexts where perfect predictions remain unattainable. We begin by demonstrating that GPT-4 and other language models can outperform existing methods in the literature. Next, we explore their generalization, revealing that GPT-4 and RoBERTa-large exhibit critical differences in failure modes, which offer potential for significant performance improvements. Finally, we show that these models can be employed in soft classification frameworks to better quantify uncertainty. We find that models with inferior hard classification results can achieve superior soft classification performance. Overall, this research lays groundwork for future tools that can drive real-world progress on misinformation.