 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Backpropagation Algorithm with Consequentialism Weight Updates over Mini-Batches
Paper and Code
Mar 11, 2020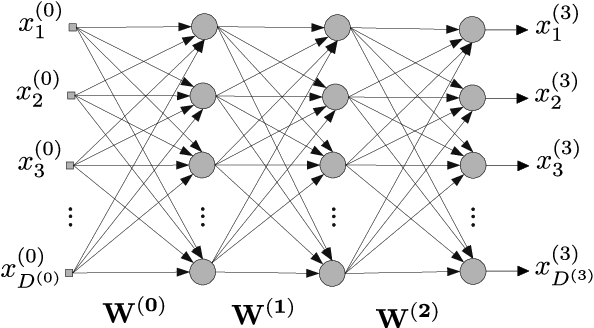
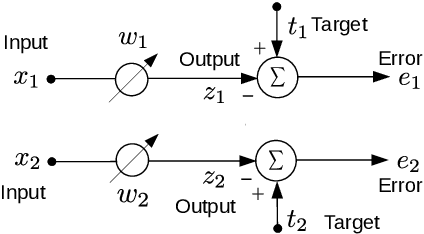
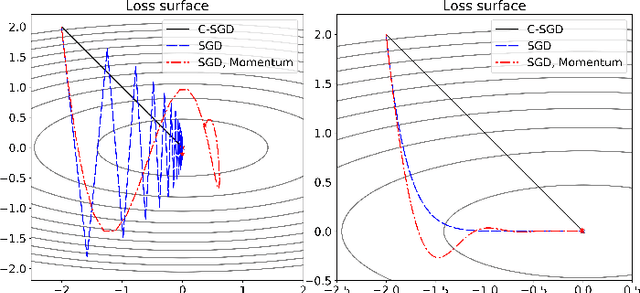
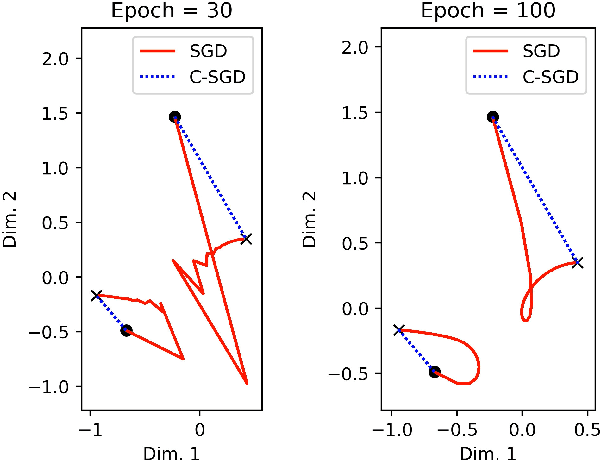
Least mean squares (LMS) is a particular case of the backpropagation (BP) algorithm applied to single-layer neural networks with the mean squared error (MSE) loss. One drawback of the LMS is that the instantaneous weight update is proportional to the square of the norm of the input vector. Normalized least mean squares (NLMS) algorithm amends this drawback by dividing the weight changes by the square of the norm of the input vector. The affine projection algorithm (APA) improved the NLMS algorithm to weight update over a batch of recently seen samples. However, the application of NLMS and APA had been limited to single-layer networks and adaptive filters. In this paper, we consider a virtual target for each neuron of a multi-layer neural network and show that the BP algorithm is equivalent to training the weights of each layer using these virtual targets and the LMS algorithm. We also introduce a consequentialism interpretation of the NLMS and the APA algorithms that justifies their use in multi-layer neural networks. Given any optimization algorithm based on the BP over mini-batches, we propose a novel consequentialism method for updating the weights.Consequently, our proposed weight update can be applied both to plain stochastic gradient descent (SGD) and to momentum methods like RMSProp, Adam, and NAG. These ideas helped us to update the weights more carefully in such a way that minimization of the loss for one sample of the mini-batch does not interfere with other samples in that mini-batch. Our experiments show the usefulness of the proposed method in optimizing deep neural network architectures.