 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgument Component Classification for Classroom Discussions
Paper and Code
Sep 06, 2019
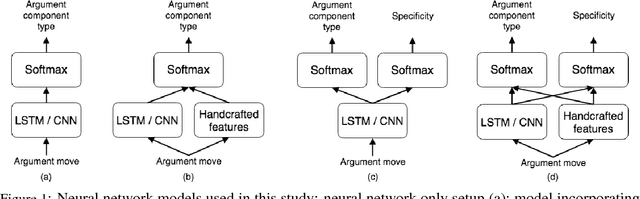

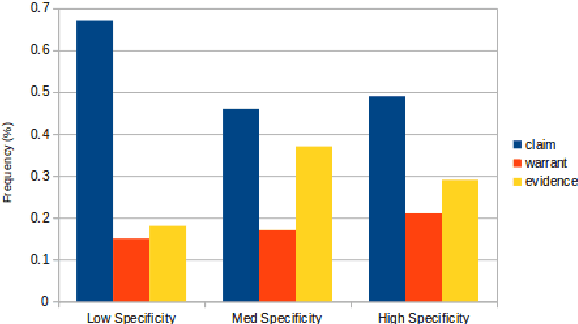
This paper focuses on argument component classification for transcribed spoken classroom discussions, with the goal of automatically classifying student utterances into claims, evidence, and warrants. We show that an existing method for argument component classification developed for another educationally-oriented domain performs poorly on our dataset. We then show that feature sets from prior work on argument mining for student essays and online dialogues can be used to improve performance considerably. We also provide a comparison between convolutional neural networks and recurrent neural networks when trained under different conditions to classify argument components in classroom discussions. While neural network models are not always able to outperform a logistic regression model, we were able to gain some useful insights: convolutional networks are more robust than recurrent networks both at the character and at the word level, and specificity information can help boost performance in multi-task training.