 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre We There Yet? Learning to Localize in Embodied Instruction Following
Paper and Code



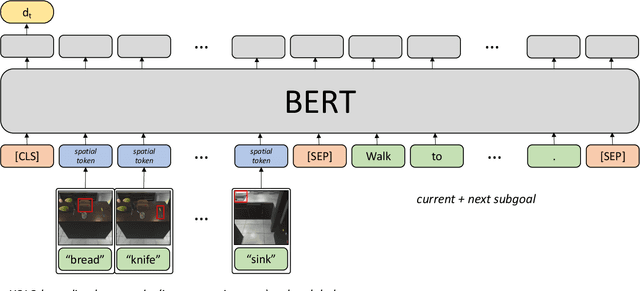
Embodied instruction following is a challenging problem requiring an agent to infer a sequence of primitive actions to achieve a goal environment state from complex language and visual inputs. Action Learning From Realistic Environments and Directives (ALFRED) is a recently proposed benchmark for this problem consisting of step-by-step natural language instructions to achieve subgoals which compose to an ultimate high-level goal. Key challenges for this task include localizing target locations and navigating to them through visual inputs, and grounding language instructions to visual appearance of objects. To address these challenges, in this study, we augment the agent's field of view during navigation subgoals with multiple viewing angles, and train the agent to predict its relative spatial relation to the target location at each timestep. We also improve language grounding by introducing a pre-trained object detection module to the model pipeline. Empirical studies show that our approach exceeds the baseline model performance.