 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Cluster Validity Measures (In)valid?
Paper and Code
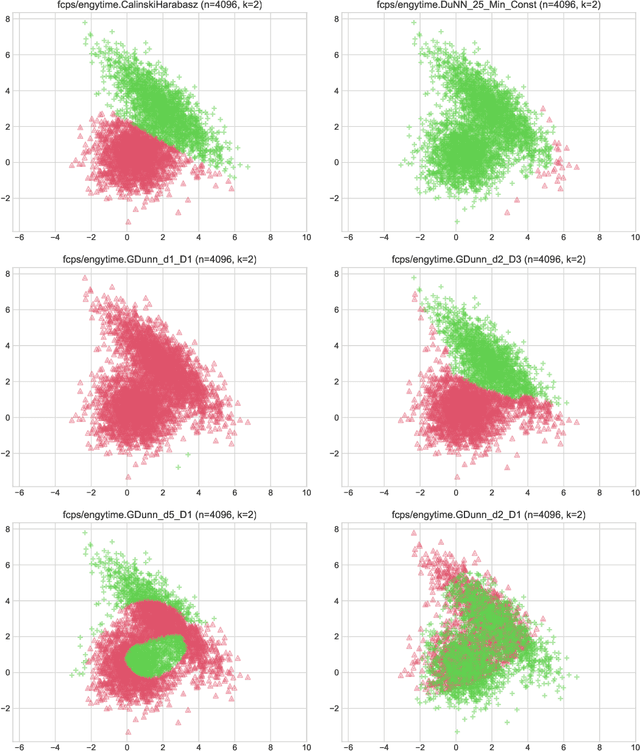
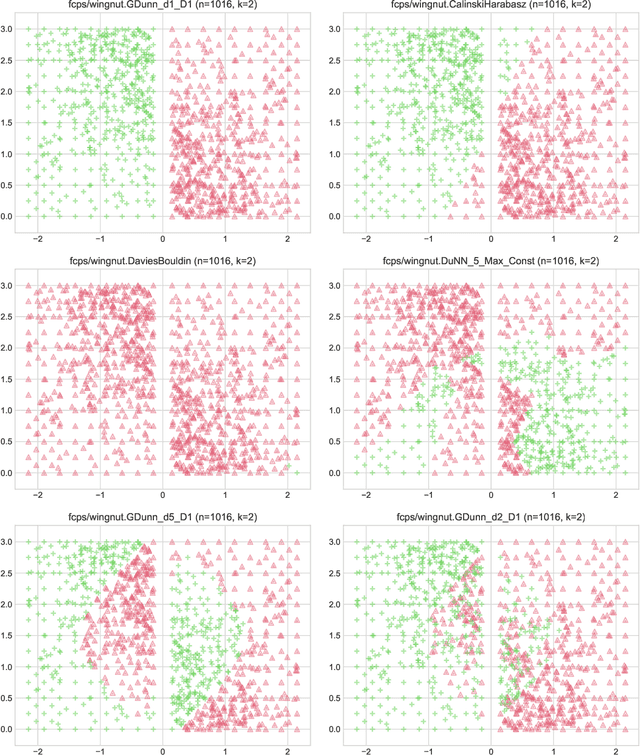
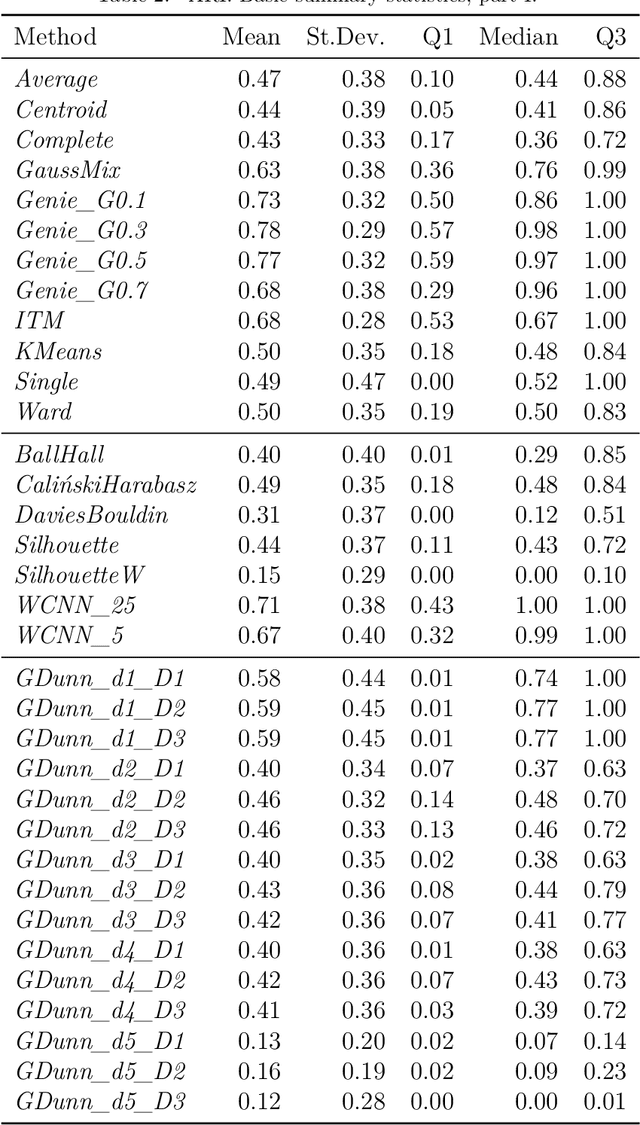
Internal cluster validity measures (such as the Calinski-Harabasz, Dunn, or Davies-Bouldin indices) are frequently used for selecting the appropriate number of partitions a dataset should be split into. In this paper we consider what happens if we treat such indices as objective functions in unsupervised learning activities. Is the optimal grouping with regards to, say, the Silhouette index really meaningful? It turns out that many cluster (in)validity indices promote clusterings that match expert knowledge quite poorly. We also introduce a new, well-performing variant of the Dunn index that is built upon OWA operators and the near-neighbour graph so that subspaces of higher density, regardless of their shapes, can be separated from each other better.