 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Diacritic Recovery Using a Feature-Rich biLSTM Model
Paper and Code
Feb 04, 2020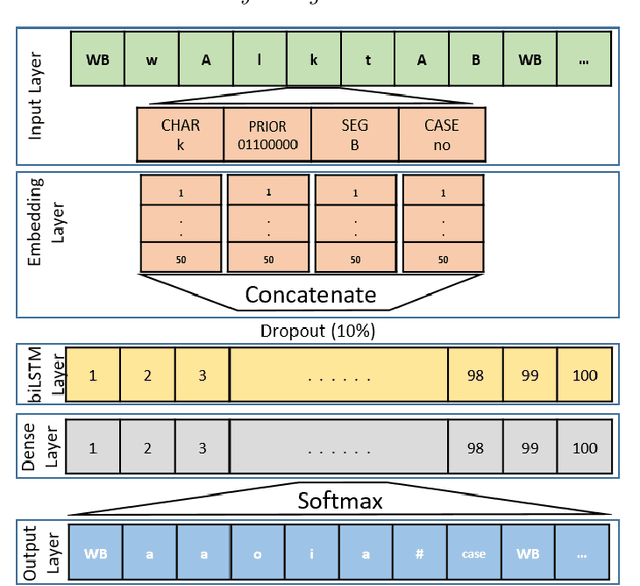
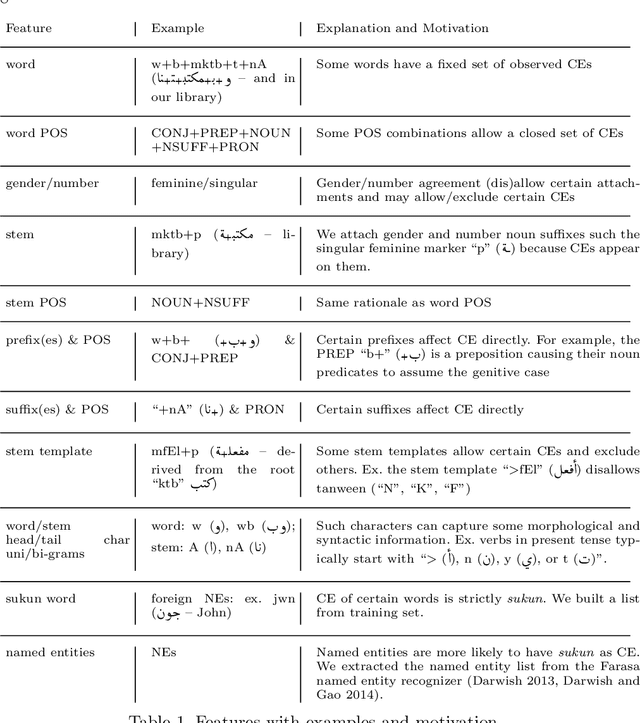
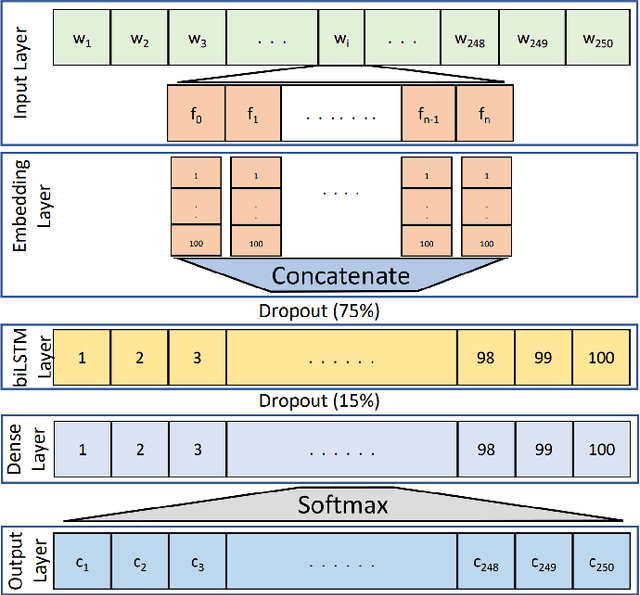
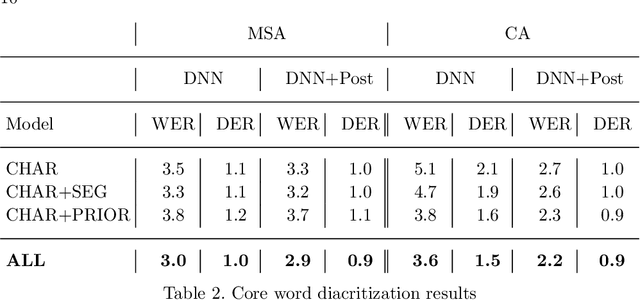
Diacritics (short vowels) are typically omitted when writing Arabic text, and readers have to reintroduce them to correctly pronounce words. There are two types of Arabic diacritics: the first are core-word diacritics (CW), which specify the lexical selection, and the second are case endings (CE), which typically appear at the end of the word stem and generally specify their syntactic roles. Recovering CEs is relatively harder than recovering core-word diacritics due to inter-word dependencies, which are often distant. In this paper, we use a feature-rich recurrent neural network model that uses a variety of linguistic and surface-level features to recover both core word diacritics and case endings. Our model surpasses all previous state-of-the-art systems with a CW error rate (CWER) of 2.86\% and a CE error rate (CEER) of 3.7% for Modern Standard Arabic (MSA) and CWER of 2.2% and CEER of 2.5% for Classical Arabic (CA). When combining diacritized word cores with case endings, the resultant word error rate is 6.0% and 4.3% for MSA and CA respectively. This highlights the effectiveness of feature engineering for such deep neural models.