 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximation with Tensor Networks. Part II: Approximation Rates for Smoothness Classes
Paper and Code
Jul 02, 2020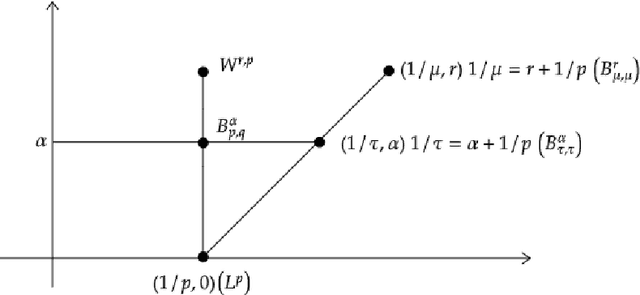
We study the approximation by tensor networks (TNs) of functions from classical smoothness classes. The considered approximation tool combines a tensorization of functions in $L^p([0,1))$, which allows to identify a univariate function with a multivariate function (or tensor), and the use of tree tensor networks (the tensor train format) for exploiting low-rank structures of multivariate functions. The resulting tool can be interpreted as a feed-forward neural network, with first layers implementing the tensorization, interpreted as a particular featuring step, followed by a sum-product network with sparse architecture. In part I of this work, we presented several approximation classes associated with different measures of complexity of tensor networks and studied their properties. In this work (part II), we show how classical approximation tools, such as polynomials or splines (with fixed or free knots), can be encoded as a tensor network with controlled complexity. We use this to derive direct (Jackson) inequalities for the approximation spaces of tensor networks. This is then utilized to show that Besov spaces are continuously embedded into these approximation spaces. In other words, we show that arbitrary Besov functions can be approximated with optimal or near to optimal rate. We also show that an arbitrary function in the approximation class possesses no Besov smoothness, unless one limits the depth of the tensor network.