 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Multi-Agent Fitted Q Iteration
Paper and Code
Apr 19, 2021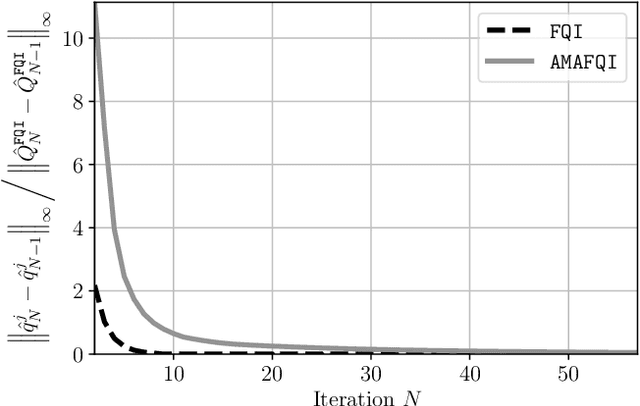
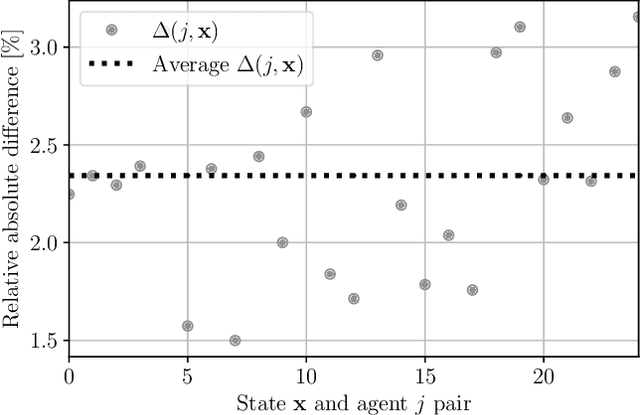
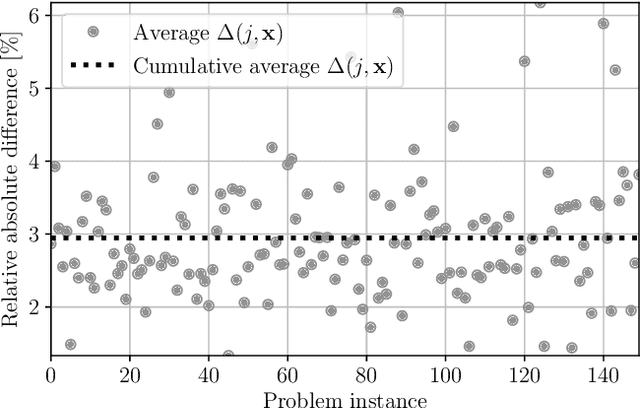

We formulate an efficient approximation for multi-agent batch reinforcement learning, the approximate multi-agent fitted Q iteration (AMAFQI). We present a detailed derivation of our approach. We propose an iterative policy search and show that it yields a greedy policy with respect to multiple approximations of the centralized, standard Q-function. In each iteration and policy evaluation, AMAFQI requires a number of computations that scales linearly with the number of agents whereas the analogous number of computations increase exponentially for the fitted Q iteration (FQI), one of the most commonly used approaches in batch reinforcement learning. This property of AMAFQI is fundamental for the design of a tractable multi-agent approach. We evaluate the performance of AMAFQI and compare it to FQI in numerical simulations. Numerical examples illustrate the significant computation time reduction when using AMAFQI instead of FQI in multi-agent problems and corroborate the similar decision-making performance of both approaches.