 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAppearance-based indoor localization: A comparison of patch descriptor performance
Paper and Code
Mar 11, 2015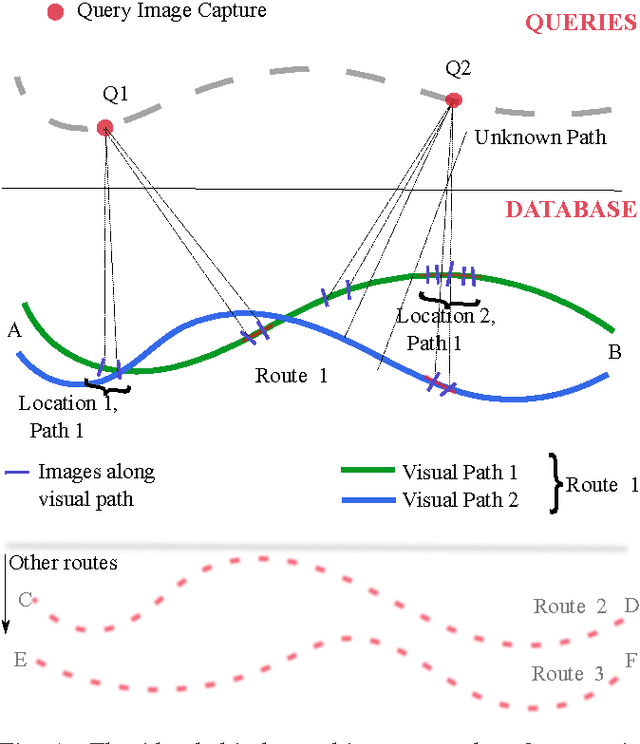

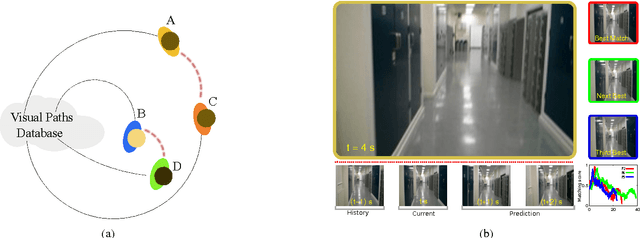
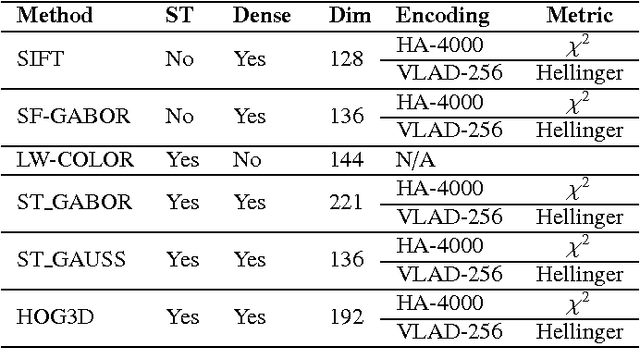
Vision is one of the most important of the senses, and humans use it extensively during navigation. We evaluated different types of image and video frame descriptors that could be used to determine distinctive visual landmarks for localizing a person based on what is seen by a camera that they carry. To do this, we created a database containing over 3 km of video-sequences with ground-truth in the form of distance travelled along different corridors. Using this database, the accuracy of localization - both in terms of knowing which route a user is on - and in terms of position along a certain route, can be evaluated. For each type of descriptor, we also tested different techniques to encode visual structure and to search between journeys to estimate a user's position. The techniques include single-frame descriptors, those using sequences of frames, and both colour and achromatic descriptors. We found that single-frame indexing worked better within this particular dataset. This might be because the motion of the person holding the camera makes the video too dependent on individual steps and motions of one particular journey. Our results suggest that appearance-based information could be an additional source of navigational data indoors, augmenting that provided by, say, radio signal strength indicators (RSSIs). Such visual information could be collected by crowdsourcing low-resolution video feeds, allowing journeys made by different users to be associated with each other, and location to be inferred without requiring explicit mapping. This offers a complementary approach to methods based on simultaneous localization and mapping (SLAM) algorithms.