 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPNet2: High-quality and High-efficiency Neural Vocoder with Direct Prediction of Amplitude and Phase Spectra
Paper and Code



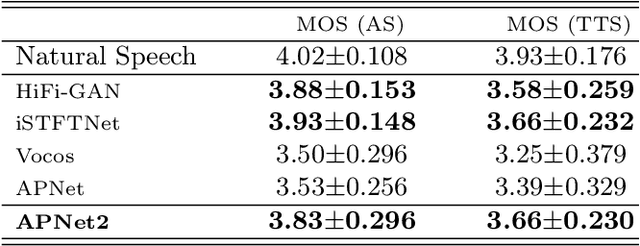
In our previous work, we proposed a neural vocoder called APNet, which directly predicts speech amplitude and phase spectra with a 5 ms frame shift in parallel from the input acoustic features, and then reconstructs the 16 kHz speech waveform using inverse short-time Fourier transform (ISTFT). APNet demonstrates the capability to generate synthesized speech of comparable quality to the HiFi-GAN vocoder but with a considerably improved inference speed. However, the performance of the APNet vocoder is constrained by the waveform sampling rate and spectral frame shift, limiting its practicality for high-quality speech synthesis. Therefore, this paper proposes an improved iteration of APNet, named APNet2. The proposed APNet2 vocoder adopts ConvNeXt v2 as the backbone network for amplitude and phase predictions, expecting to enhance the modeling capability. Additionally, we introduce a multi-resolution discriminator (MRD) into the GAN-based losses and optimize the form of certain losses. At a common configuration with a waveform sampling rate of 22.05 kHz and spectral frame shift of 256 points (i.e., approximately 11.6ms), our proposed APNet2 vocoder outperformed the original APNet and Vocos vocoders in terms of synthesized speech quality. The synthesized speech quality of APNet2 is also comparable to that of HiFi-GAN and iSTFTNet, while offering a significantly faster inference speed.