 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnticipating the Long-Term Effect of Online Learning in Control
Paper and Code
Jul 24, 2020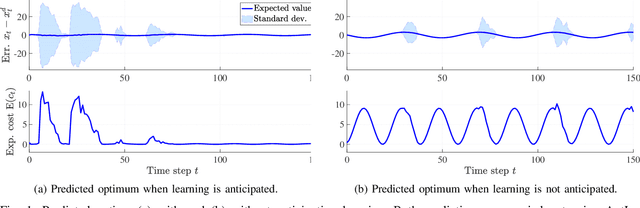


Control schemes that learn using measurement data collected online are increasingly promising for the control of complex and uncertain systems. However, in most approaches of this kind, learning is viewed as a side effect that passively improves control performance, e.g., by updating a model of the system dynamics. Determining how improvements in control performance due to learning can be actively exploited in the control synthesis is still an open research question. In this paper, we present AntLer, a design algorithm for learning-based control laws that anticipates learning, i.e., that takes the impact of future learning in uncertain dynamic settings explicitly into account. AntLer expresses system uncertainty using a non-parametric probabilistic model. Given a cost function that measures control performance, AntLer chooses the control parameters such that the expected cost of the closed-loop system is minimized approximately. We show that AntLer approximates an optimal solution arbitrarily accurately with probability one. Furthermore, we apply AntLer to a nonlinear system, which yields better results compared to the case where learning is not anticipated.