 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnonymising Queries by Semantic Decomposition
Paper and Code
Sep 12, 2019
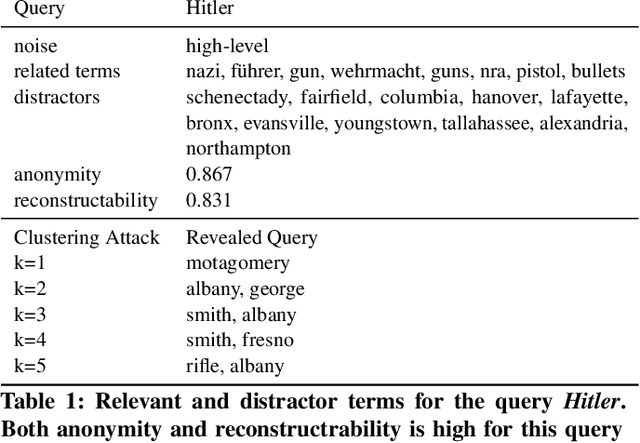

Protecting the privacy of search engine users is an important requirement in many information retrieval scenarios. A user might not want a search engine to guess his or her information need despite requesting relevant results. We propose a method to protect the privacy of search engine users by decomposing the queries using semantically \emph{related} and unrelated \emph{distractor} terms. Instead of a single query, the search engine receives multiple decomposed query terms. Next, we reconstruct the search results relevant to the original query term by aggregating the search results retrieved for the decomposed query terms. We show that the word embeddings learnt using a distributed representation learning method can be used to find semantically related and distractor query terms. We derive the relationship between the \emph{anonymity} achieved through the proposed query anonymisation method and the \emph{reconstructability} of the original search results using the decomposed queries. We analytically study the risk of discovering the search engine users' information intents under the proposed query anonymisation method, and empirically evaluate its robustness against clustering-based attacks. Our experimental results show that the proposed method can accurately reconstruct the search results for user queries, without compromising the privacy of the search engine users.