 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnimating Face using Disentangled Audio Representations
Paper and Code
Oct 02, 2019
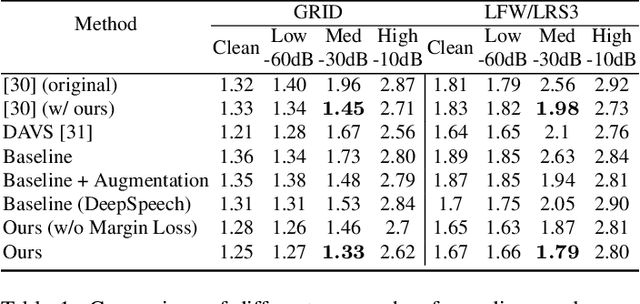
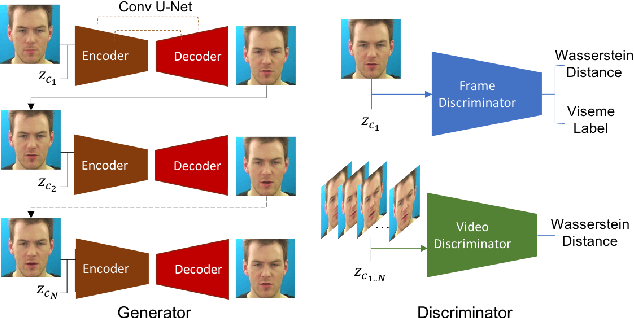
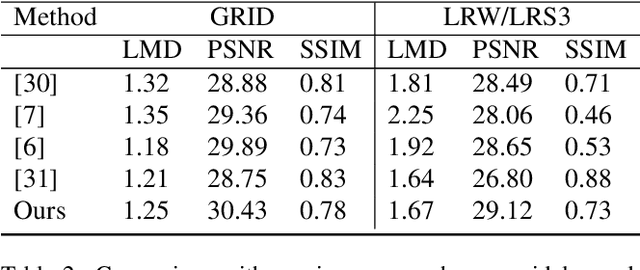
All previous methods for audio-driven talking head generation assume the input audio to be clean with a neutral tone. As we show empirically, one can easily break these systems by simply adding certain background noise to the utterance or changing its emotional tone (to such as sad). To make talking head generation robust to such variations, we propose an explicit audio representation learning framework that disentangles audio sequences into various factors such as phonetic content, emotional tone, background noise and others. We conduct experiments to validate that conditioned on disentangled content representation, the generated mouth movement by our model is significantly more accurate than previous approaches (without disentangled learning) in the presence of noise and emotional variations. We further demonstrate that our framework is compatible with current state-of-the-art approaches by replacing their original audio learning component with ours. To our best knowledge, this is the first work which improves the performance of talking head generation from disentangled audio representation perspective, which is important for many real-world applications.