Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAncient-Modern Chinese Translation with a Large Training Dataset
Paper and Code
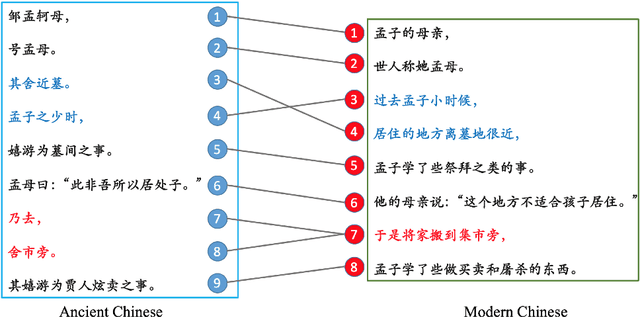
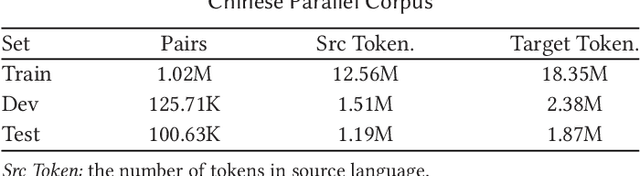
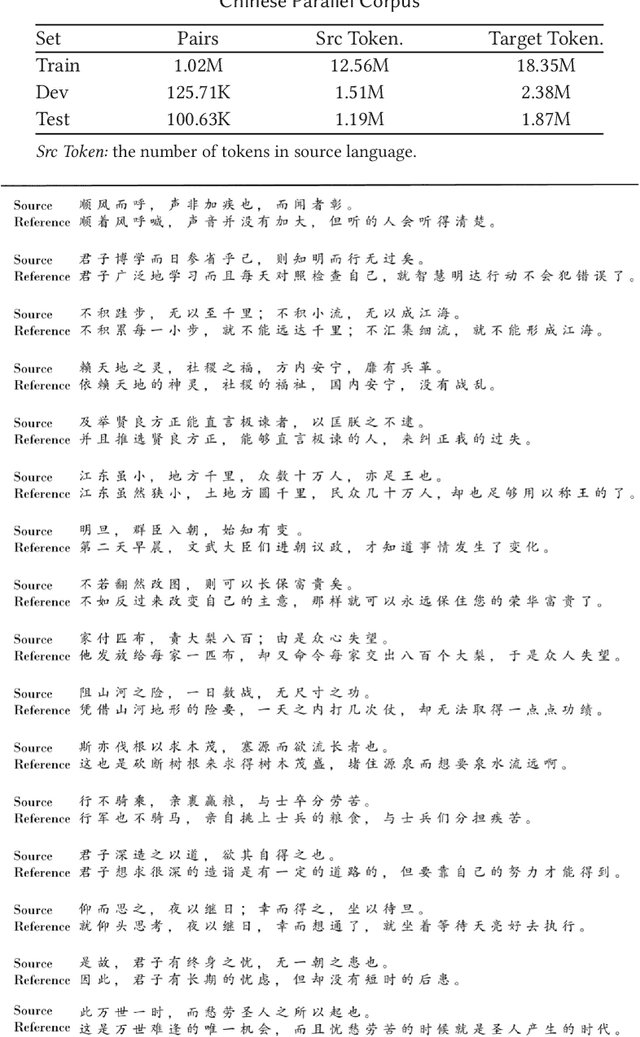
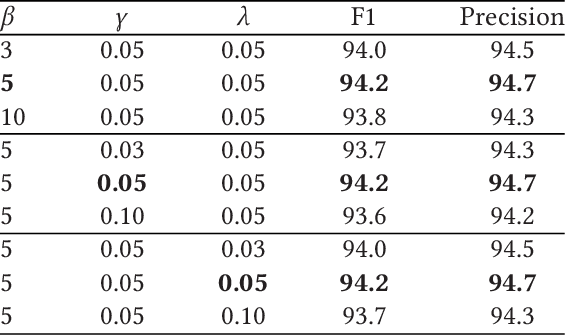
Ancient Chinese brings the wisdom and spirit culture of the Chinese nation. Automatically translation from ancient Chinese to modern Chinese helps to inherit and carry forward the quintessence of the ancients. In this paper, we propose an Ancient-Modern Chinese clause alignment approach and apply it to create a large scale Ancient-Modern Chinese parallel corpus which contains about 1.24M bilingual pairs. To our best knowledge, this is the first large high-quality Ancient-Modern Chinese dataset. Furthermore, we train the SMT and various NMT based models on this dataset and provide a strong baseline for this task
* 8 pages, 2 figures
View paper on