 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomically-Grounded Fact Checking of Automated Chest X-ray Reports
Paper and Code
Dec 03, 2024
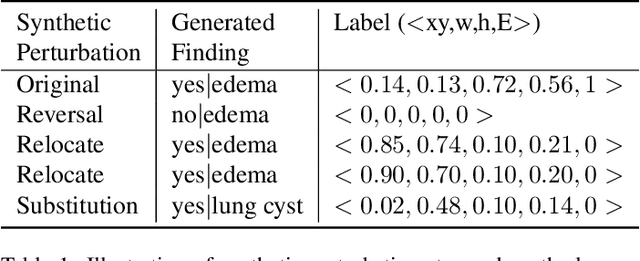
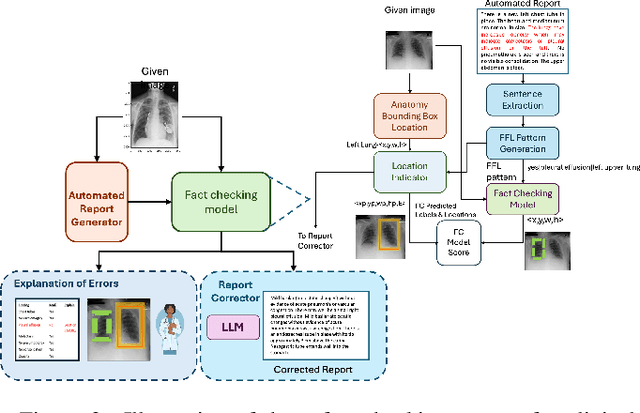
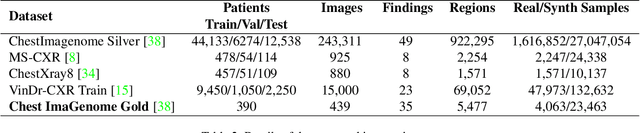
With the emergence of large-scale vision-language models, realistic radiology reports may be generated using only medical images as input guided by simple prompts. However, their practical utility has been limited due to the factual errors in their description of findings. In this paper, we propose a novel model for explainable fact-checking that identifies errors in findings and their locations indicated through the reports. Specifically, we analyze the types of errors made by automated reporting methods and derive a new synthetic dataset of images paired with real and fake descriptions of findings and their locations from a ground truth dataset. A new multi-label cross-modal contrastive regression network is then trained on this datsaset. We evaluate the resulting fact-checking model and its utility in correcting reports generated by several SOTA automated reporting tools on a variety of benchmark datasets with results pointing to over 40\% improvement in report quality through such error detection and correction.