 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Word Translation of Transformer Layers
Paper and Code
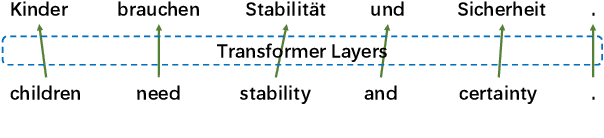
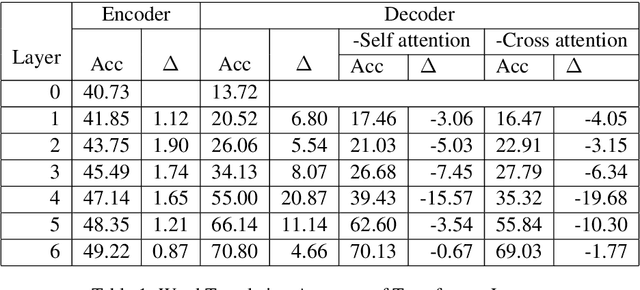
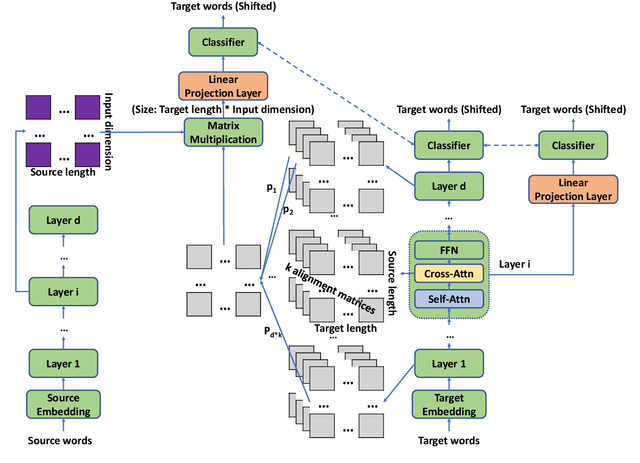
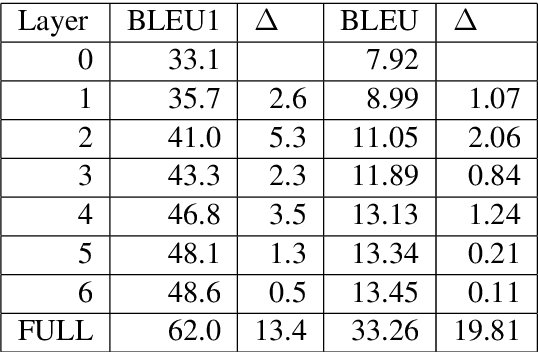
The Transformer translation model is popular for its effective parallelization and performance. Though a wide range of analysis about the Transformer has been conducted recently, the role of each Transformer layer in translation has not been studied to our knowledge. In this paper, we propose approaches to analyze the translation performed in encoder / decoder layers of the Transformer. Our approaches in general project the representations of an analyzed layer to the pre-trained classifier and measure the word translation accuracy. For the analysis of encoder layers, our approach additionally learns a weight vector to merge multiple attention matrices into one and transform the source encoding to the target side with the merged alignment matrix to align source tokens with target translations while bridging different input - output lengths. While analyzing decoder layers, we additionally study the effects of the source context and the decoding history in word prediction through bypassing the corresponding self-attention or cross-attention sub-layers. Our analysis reveals that the translation starts at the very beginning of the "encoding" (specifically at the source word embedding layer), and shows how translation evolves during the forward computation of layers. Based on observations gained in our analysis, we propose that increasing encoder depth while removing the same number of decoder layers can simply but significantly boost the decoding speed. Furthermore, simply inserting a linear projection layer before the decoder classifier which shares the weight matrix with the embedding layer can effectively provide small but consistent and significant improvements in our experiments on the WMT 14 English-German, English-French and WMT 15 Czech-English translation tasks (+0.42, +0.37 and +0.47 respectively).