 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Robustness of End-to-End Neural Models for Automatic Speech Recognition
Paper and Code
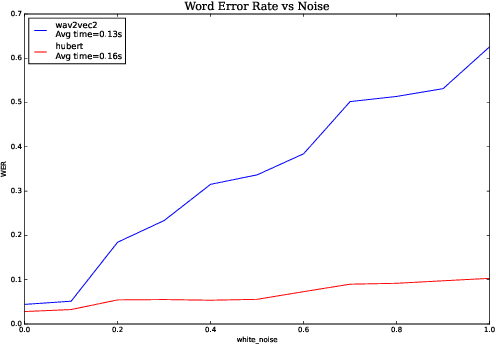
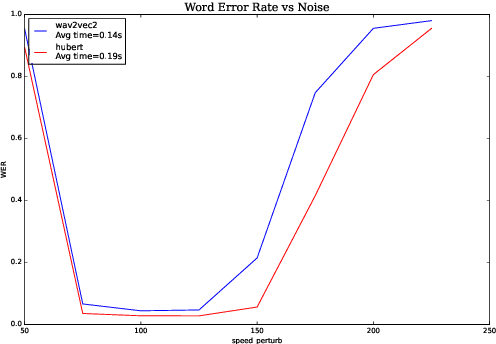
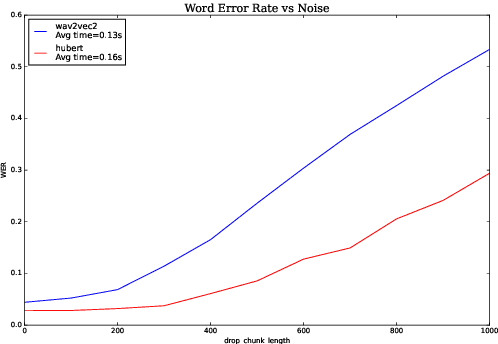
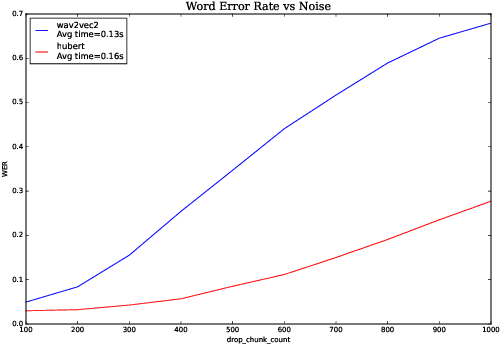
We investigate robustness properties of pre-trained neural models for automatic speech recognition. Real life data in machine learning is usually very noisy and almost never clean, which can be attributed to various factors depending on the domain, e.g. outliers, random noise and adversarial noise. Therefore, the models we develop for various tasks should be robust to such kinds of noisy data, which led to the thriving field of robust machine learning. We consider this important issue in the setting of automatic speech recognition. With the increasing popularity of pre-trained models, it's an important question to analyze and understand the robustness of such models to noise. In this work, we perform a robustness analysis of the pre-trained neural models wav2vec2, HuBERT and DistilHuBERT on the LibriSpeech and TIMIT datasets. We use different kinds of noising mechanisms and measure the model performances as quantified by the inference time and the standard Word Error Rate metric. We also do an in-depth layer-wise analysis of the wav2vec2 model when injecting noise in between layers, enabling us to predict at a high level what each layer learns. Finally for this model, we visualize the propagation of errors across the layers and compare how it behaves on clean versus noisy data. Our experiments conform the predictions of Pasad et al. [2021] and also raise interesting directions for future work.