 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Finite Neural Networks: Can We Trust Neural Tangent Kernel Theory?
Paper and Code
Dec 08, 2020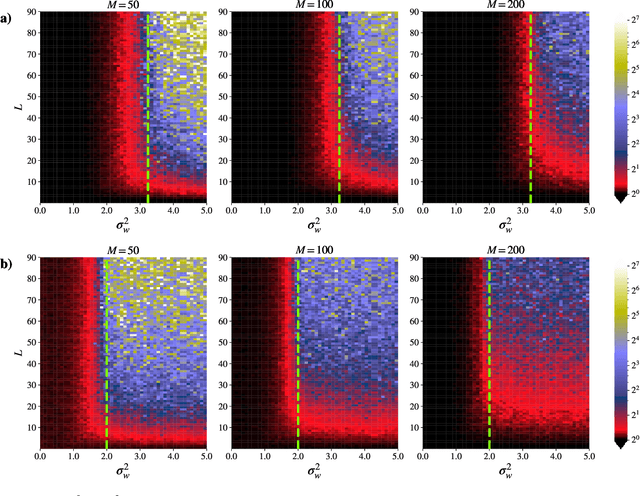
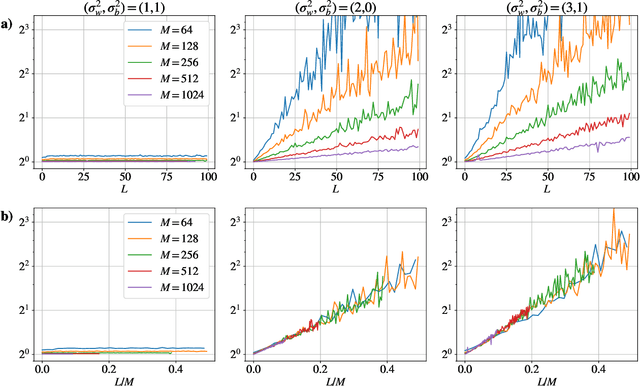
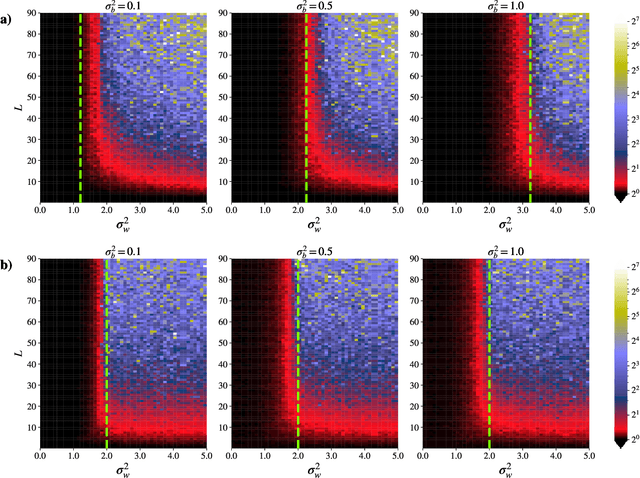
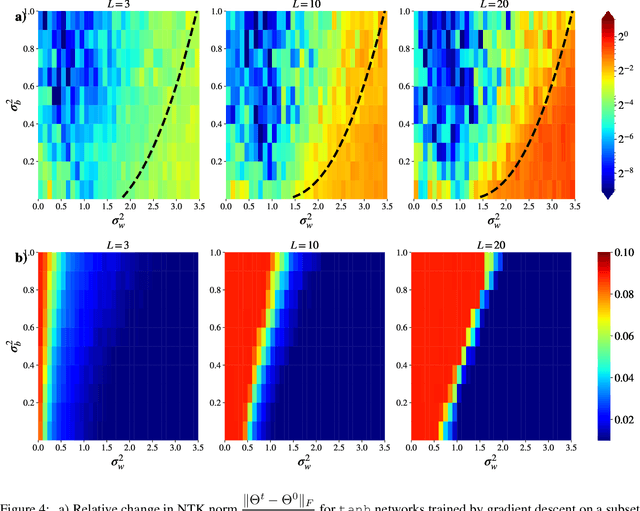
Neural Tangent Kernel (NTK) theory is widely used to study the dynamics of infinitely-wide deep neural networks (DNNs) under gradient descent. But do the results for infinitely-wide networks give us hints about the behaviour of real finite-width ones? In this paper we study empirically when NTK theory is valid in practice for fully-connected ReLu and sigmoid networks. We find out that whether a network is in the NTK regime depends on the hyperparameters of random initialization and network's depth. In particular, NTK theory does not explain behaviour of sufficiently deep networks initialized so that their gradients explode: the kernel is random at initialization and changes significantly during training, contrary to NTK theory. On the other hand, in case of vanishing gradients DNNs are in the NTK regime but become untrainable rapidly with depth. We also describe a framework to study generalization properties of DNNs by means of NTK theory and discuss its limits.