 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of training and seed bias in small molecules generated with a conditional graph-based variational autoencoder -- Insights for practical AI-driven molecule generation
Paper and Code
Jul 19, 2021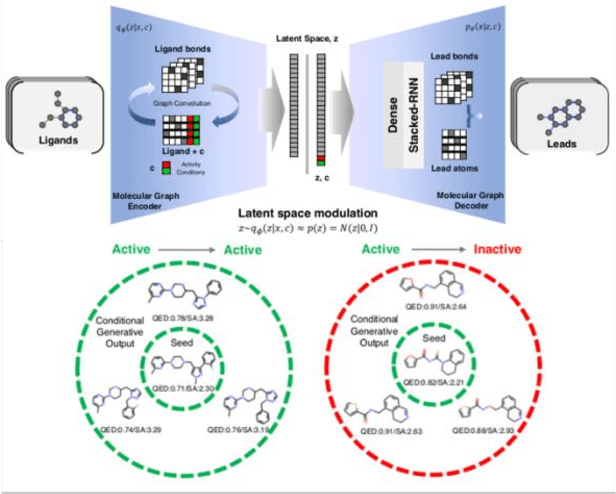
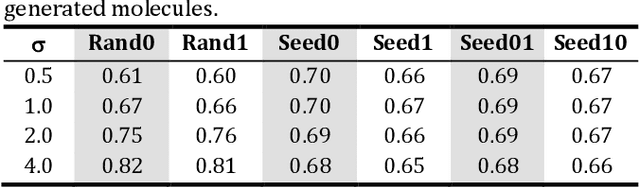
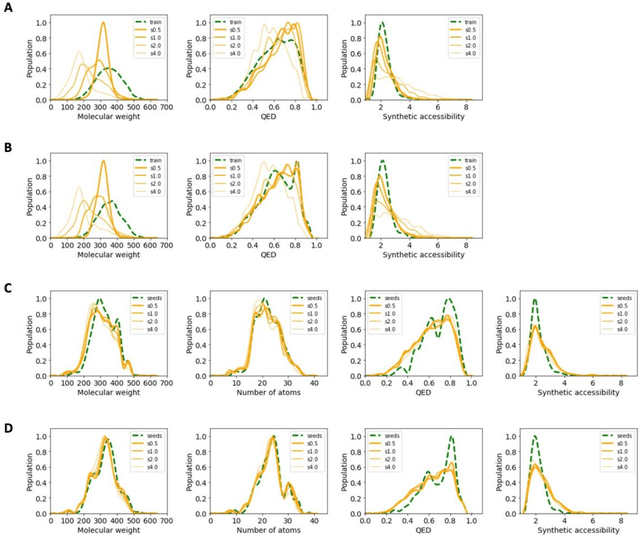
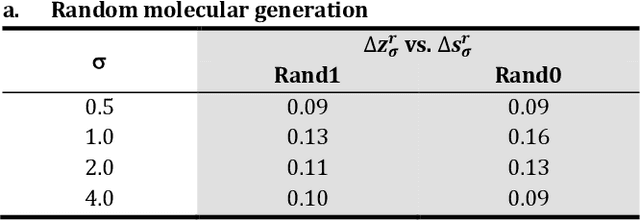
The application of deep learning to generative molecule design has shown early promise for accelerating lead series development. However, questions remain concerning how factors like training, dataset, and seed bias impact the technology's utility to medicine and computational chemists. In this work, we analyze the impact of seed and training bias on the output of an activity-conditioned graph-based variational autoencoder (VAE). Leveraging a massive, labeled dataset corresponding to the dopamine D2 receptor, our graph-based generative model is shown to excel in producing desired conditioned activities and favorable unconditioned physical properties in generated molecules. We implement an activity swapping method that allows for the activation, deactivation, or retention of activity of molecular seeds, and we apply independent deep learning classifiers to verify the generative results. Overall, we uncover relationships between noise, molecular seeds, and training set selection across a range of latent-space sampling procedures, providing important insights for practical AI-driven molecule generation.