 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Thompson Sampling for Gaussian Process Optimization in the Bandit Setting
Paper and Code
Feb 12, 2018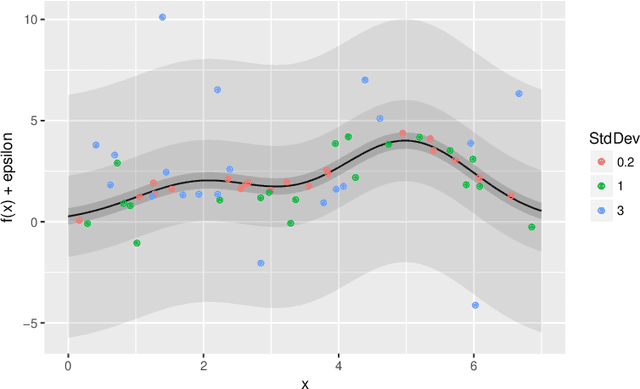
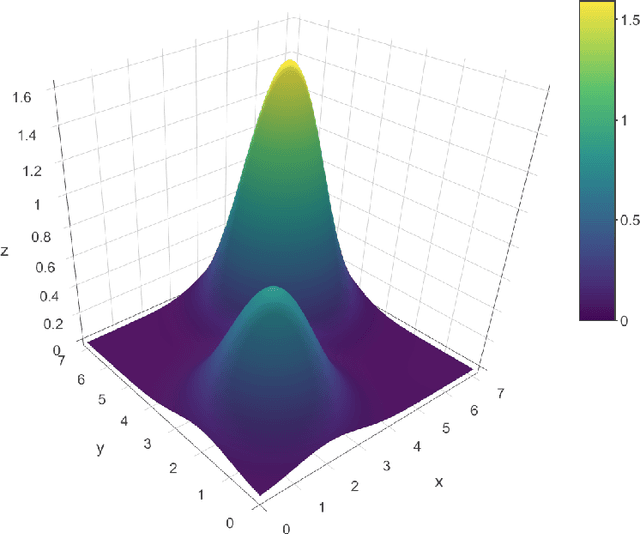
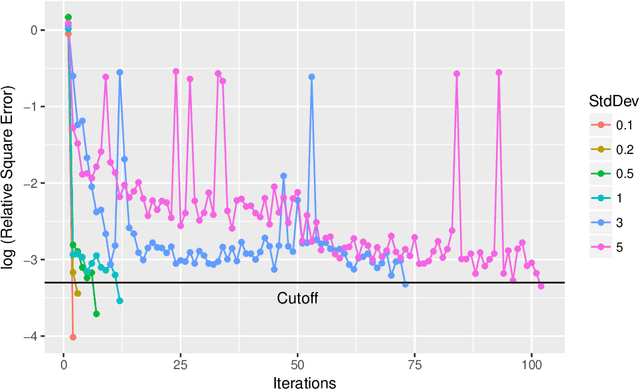
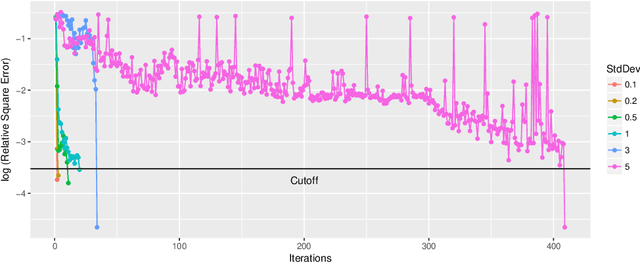
We consider the global optimization of a function over a continuous domain. At every evaluation attempt, we can observe the function at a chosen point in the domain and we reap the reward of the value observed. We assume that drawing these observations are expensive and noisy. We frame it as a continuum-armed bandit problem with a Gaussian Process prior on the function. In this regime, most algorithms have been developed to minimize some form of regret. Contrary to this popular norm, in this paper, we study the convergence of the sequential point $\boldsymbol{x}^t$ to the global optimizer $\boldsymbol{x}^*$ for the Thompson Sampling approach. Under some assumptions and regularity conditions, we show an exponential rate of convergence to the true optimal.